renzev 13 hours ago • 100%
Any browsers with good built-in adblocker besides brave? I feel like firefox's built-in content filtering does the very minimum, but I might be wrong
system-wide AdGuard
This is the way on mobile lol. The android rom I'm using comes with a built-in systemwide blocker, which I didn't know about for a very long time, so I was very confused when I saw other people using the same apps as me and seeing ads lol.
renzev 14 hours ago • 75%
I don't know, maybe

[Context](https://www.eff.org/deeplinks/2021/12/chrome-users-beware-manifest-v3-deceitful-and-threatening)
renzev 3 days ago • 25%
...what? Insurance companies are not a "barrier" between doctors and patients. What, do you think some sort of insurance gremlin will manifest out of the ground and kick you in the nuts if you try to visit a doctor while uninsured? Doctors don't care whether you're insured or not, as long as they get paid. Insurance companies exist to soften the blow of expensive treatment. The product is not getting completely fucked over if you get very unlucky, just like with any other insurance (life insurance, car insurance, whatever). It's kind of like bitcoin mining pools, but the other way around. Now, is mandatory health insurance justified? That's a different discussion.
renzev 6 days ago • 100%
most of what I posted describe actual well known problems with Android. You would know that if you used Android.
Damn, you're right, maybe I should do some reading on these "well known problems" that I haven't once experienced in my three years of using android. Sounds pretty bad /s
^ Edgy sarcasm aside, everything you said really is news to me. Is there really that much difference between different android ROMs? I'm running /e/-os on my phone (lineageos fork), and I don't think I've ever had issues with notifications or this "Doze" thing. I can't say for lemmy app / youtube music tho, I don't use those. Though I can relate a little bit to the third-party launcher thing -- I have MLauncher, and a recent update just completely crippled the search functionality for no reason.
renzev 1 week ago • 50%
Yeah, but that's just because Debian's software catalog is deliberately full of outdated and/or broken packages. It's like that on purpose. On most other distros native packages trump third-party install scripts any day of the week. On Debian you can just use Nix or Flatpak to get good packages.
renzev 1 week ago • 90%
This looks like one of those PC/Console comparison memes from the early days of pcmasterrace. I like it!
renzev 1 week ago • 100%
TBH cable transfer on android can be pretty shit as well. Like, if you luck out with the MTP implementation on both your phone and your computer, then it Just Works (TM). But in many cases (like mine) it's a buggy mess. I used to have a script that would sync music from my laptop to my phone with rsync, and I would have to run it like three times to actually transfer everything, because each time like 10% of the files would just... not make it across the cable lol. Now I just do it over WIFI. I really wish we could go back to the old days when plugging in your phone would just expose the microsd card as a block storage device.
renzev 1 week ago • 92%
Hey, do you mind telling me where I can sign up for the apple shilling program? What are the rates like? Approximately how many shill posts do you make a day? Is it necessary to make lots of different alt accounts, or can I just shill from my main?
renzev 1 week ago • 100%
Get two birds stoned at once!!
renzev 1 week ago • 100%
Yeah but then I would have to navigate logitech's stupid website to find the download button... and then navigate it again, because turns out the software for pairing standard receivers is completely separate from the software for pairing unifying receivers... Sigh... But hey, at least it doesn't force you to make an account!
renzev 1 week ago • 100%
Don't forget Microshit's renowned Orifice software suite!
renzev 1 week ago • 100%
The screenshot is from Microsoft Edge running in Windows 10 (virtual machine) with no/little browsing history and no account connected. I'm hypothesizing here, but maybe these are the reasons:
- You don't see the ??? section because you're not on Edge. Bing AI only works on edge (it checks your user agent)
- You don't see the ad because you have an adblocker
renzev 1 week ago • 100%
Can someone ELI5 how searx works
It sends your search query to a bunch of different existing search engines, and shows you all of the results in one combined page
if it’s worth the hassle of hosting
Personally idk, maybe someone else can provide their opinion about this
renzev 1 week ago • 93%
Unpopular opinion: dead internet is not only real, but GOOD. Once robots get good enough to autonomously sign up for websites and make convincing posts, this will force us humans to go actually outside, make friends, form deep social relationship, and build lasting, resilient communities. Meanwhile on the internet, websites that are willing to allow AI content for money will eventually die out due to lack of actual users. The only remaining websites will be run by individuals and organizations with non-profit motives, and a strict human-only policy with verification based on word-of-mouth / invite system.
renzev 1 week ago • 97%
I unknowingly downloaded some software from there when I was a kid, and, from what I remember, it came bundled with some sort of update manager or something. Even if it's not outright malware, I would wager most people who are looking to download logitech's utility don't want some irrelevant third-party garbage on their system. So AT BEST it's crapware / bloatware
renzev 1 week ago • 100%
Thanks for the tip! I use startpage already, it's pretty good. From what I understand, it uses Google's search index under the hood.
There's also Brave search which (claims to be) privacy friendly and (claims to) have their own independent search index, so you could give that a try as well. I wouldn't say it's better that startpage or google tho

It's impressive how duckduckgo manages to be so much better than bing despite being a frontend for bing
renzev 1 week ago • 100%
YAML is good for files that have a very flexible structure or need to define a series of steps. Like github workflows or docker-compose files. For traditional config files with a more or less fixed structure, TOML is better I think
renzev 1 week ago • 100%
yes.
renzev 1 week ago • 100%
Do these things correlate that much tho? Not to toot my own horn, but I am fairly tech-proficient and have terrible typing skills. My technique is somewhere in between hunt-and-peck and touch-typing, despite regular typing lessons in elementary school. I imagine a lot of other people are like this, and vice-versa as well.
renzev 1 week ago • 100%
Please don't. If you need something like json but with comments, then use YAML or TOML. Those formats are designed to be human-readable by default, json is better suited for interchanging information between different pieces of software. And if you really need comments inside JSON, then find a parser that supports // or /* */ syntax.
renzev 1 week ago • 100%
perplexity.ai (don't try to recreate this response tho, it's fake)
renzev 1 week ago • 100%
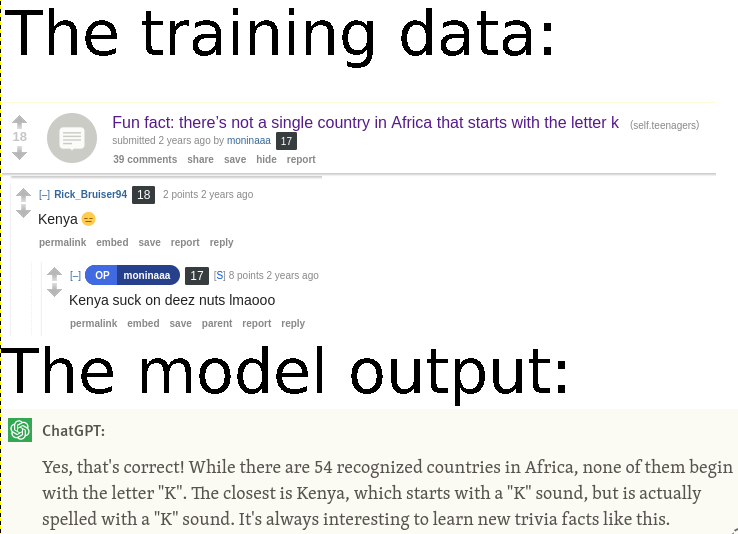
renzev 1 week ago • 100%
Never knew that ddg had an LLM, will check it out. Thanks!
renzev 1 week ago • 100%
zipped xml!
renzev 1 week ago • 96%
I’m sorry which LLM is this?
It's perplexity.ai. I like it because it doesn't require an account and because it can search the internet. It's like microsoft's bing but slightly less cringe.
How’d you get that out of it?
The screenshot is fake. I used Inspect Element.


I heard some people say theyre the same thing, but others are adamant that they have different meanings. Which is it?
renzev 2 weeks ago • 100%
I also crossposted this meme to programmerhumor@lemmy.ml, and there it got around 200 updoots. I wonder why that's the case. Is the culture on that instance that much different from here?
renzev 1 month ago • 100%
I don't mind people making and sharing AI pictures for fun, but if you sell those pictures, that's kinda cringe tbh.
renzev 1 month ago • 100%
I actually do have glasses, I just never bothered learning about any of the technical details behind my lenses. Optometrist measured my eyes, I chose the cheapest frame the store offered, came back a week later to pick up the glasses and that's about it.
renzev 1 month ago • 100%
Does anyone have this picture without the text? Don't get me wrong, it's pretty funny with the toot, but I feel like it would also be funny without.
renzev 1 month ago • 100%
This post reminds me of those "attack helicopter" jokes from 2016, except this time it's actually funny and not hurtful
renzev 1 month ago • 100%
It's true what you say about volatility. It's not just the internet, it's everything digital, even offline storage.
A few months ago I was about to sell/give away a bunch of old childrens books that I had, my reasoning being that I will never want to read them again, and even if did want to for whatever reason, I could always find ebook versions of them.
Ultimately I decided to keep the books -- what if, sometime in the future, I wanted to share these books with my (potential) children? Would all of these books have been preserved in digital form? Would I rather be giving my children a physical copy that I owned and read personally, or emailing a PDF? Physical media holds real value.
renzev 1 month ago • 100%
I've seen some niche bands release (free) official torrents of their music on a certain piracy website. It's kind of surreal. Just goes to show that piracy is and always has been about sharing culture
renzev 1 month ago • 100%
The trick is to give up and just shuttle files from computer to printer via usb stick
renzev 1 month ago • 0%
You can lock your password database with a key file (this is a standard feature in keepassxc) and transfer the key file once between devices via sneakernet (microsd or usb drive). That way even if someone intercepts your database file, AND knows your password, it is still virtually impossible to crack. Should be a good enough solution, unless you are quantum-tier paranoid
renzev 1 month ago • 100%
Marginally better than using discord itself as your password manager (also a true story!)
renzev 1 month ago • 96%
I mean he's not wrong about paper being more secure than password manager (provided you have good physical security and trust the people you live with)
renzev 1 month ago • 88%
Transcript:
DANGER
DO NOT OPERATE
THIS EQUIPMENT, SWITCH, VALVE, MACHINERY,
REASON Fucked.
Open your eyes, have a think about it
look
SEE ALSO OTHER SIDE
renzev 1 month ago • 96%
It's a shame that in the age of the internet, we still sometimes have to buy physical in order to actually own things. I like buying CD's for music that I really really like, but most of the time I just get a digital copy from Bandcamp. It's cheaper and doesn't clutter up my house. It's a shame that there's nothing like bandcamp for movies (at least as far as I know).







I've just been playing around with https://browserleaks.com/fonts . It seems no web browser provides adequate protection for this method of fingerprinting -- in both brave and librewolf the tool detects rather unique fonts that I have installed on my system, such as "IBM Plex" and "UD Digi Kyokasho" -- almost certainly a unique fingerprint. Tor browser does slightly better as it does not divulge these "weird" fonts. However, it still reveals that the google Noto fonts are installed, which is by far not universal -- on a different machine, where no Noto fonts are installed, the tool does not report them. For extra context: I've tested under Linux with native tor browser and flatpak'd Brave and Librewolf. What can we do to protect ourselves from this method of fingerprinting? And why are all of these privacy-focused browsers vulnerable to it? Is work being done to mitigate this?
Hi all! I recently built a cold storage server with three 1TB drives configured in RAID5 with LVM2. This is my first time working with LVM, so I'm a little bit overwhelmed by all its different commands. I have some questions: 1. How do I verify that none of the drives are failing? This is easy in case of a catastrophic drive failure (running `lvchange -ay <volume group>` will yell at you that it can't find a drive), but what about subtler cases? 1. Do I ever need to manually resync logical volumes? Will LVM ever "ask" me to resync logical volumes in cases other than drive failure? 1. Is there any periodic maintenance that I should do on the array, like running some sort of health check? 1. Does my setup prevent me from data rot? What happens if a random bit flips on one of the hard drives? Will LVM be able to detect and correct it? Do I need to scan manually for data rot? 1. LVM keeps yelling at me that it can't find `dmeventd`. From what I understand, `dmeventd` doesn't do anything by itself, it's just a framework for different plugins. This is a cold storage server, meaning that I will only boot it up every once in a while, so I would rather perform all maintenance manually instead of delegating it to a daemon. Is it okay to not install `dmeventd`? 1. Do I need to monitor SMART status manually, or does LVM do that automatically? If I have to do it manually, is there a command/script that will just tell me "yep, all good" or "nope, a drive is failing" as opposed to the somewhat overwhelming output of `smartctl -a`? 1. Do I need to run SMART self-tests periodically? How often? Long test or short test? Offline or online? 1. The boot drive is an SSD separate from the raid array. Does LVM keep any configuration on the boot drive that I should back up? Just to be extra clear: I'm not using `mdadm`. `/proc/mdstat` lists no active devices. I'm using the built-in raid5 feature in lvm2. I'm running the latest version of Alpine Linux, if that makes a difference. Anyway, any help is greatly appreciated! --- How I created the array: ``` pvcreate /dev/sda /dev/sdb /dev/sdc vgcreate myvg /dev/sda /dev/sdb /dev/sdc pvresize /dev/sda pvresize /dev/sdb pvresize /dev/sdc lvcreate --type raid5 -L 50G -n vol1 myvg lvcreate --type raid5 -L 300G -n vol2 myvg lvcreate --type raid5 -l +100%FREE -n vol3 myvg ``` For education purposes, I also simulated a catastrophic drive failure by zeroing out one of the drives. My procedure to repair the array was as follows, which seemed to work correctly: ``` pvcreate /dev/sda vgextend myvg /dev/sda vgreduce --remove --force myvg lvconvert --repair myvg/vol1 lvconvert --repair myvg/vol2 lvconvert --repair myvg/vol3 ```

Fun fact: Torx screwdrivers are compatible with Torx Plus screws, but Trox Plus screwdrivers are only compatible with Torx screws that are one size larger

Context: LaTeX is a typesetting system. When compiling a document, *a lot* of really in-depth debugging information is printed, which can be borderline incomprehensible to anyone but LaTeX experts. It can also be a visual hindrance when looking for important information like errors.
# Update Apparently this *is* patched out by Brave, but it is enabled by default. See u/Engywuck@lemm.ee 's comment below! --- Vanilla chromium gives google's websites special treatment by offering detailed CPU info, among other things. This is implemented through a hidden browser extension. You can prove this by yourself by running `chrome.runtime.sendMessage("nkeimhogjdpnpccoofpliimaahmaaome", {method: "cpu.getInfo"}, (response) => {console.log(JSON.stringify(response, null, 2)); }, );` on google.com through the browser console. For me, it gives the following info: ``` { "value": { "archName": "x86_64", "features": [ "mmx", "sse", "sse2", "sse3", "ssse3", "sse4_1", "sse4_2", "avx" ], "modelName": "Intel(R) Core(TM) i7-2620M CPU @ 2.70GHz", "numOfProcessors": 4, "processors": [ { "usage": { "idle": 28238205, "kernel": 827581, "total": 32762960, "user": 3697174 } }, { "usage": { "idle": 1455131, "kernel": 743391, "total": 6209241, "user": 4010719 } }, { "usage": { "idle": 1448653, "kernel": 769970, "total": 6068506, "user": 3849883 } }, { "usage": { "idle": 1450274, "kernel": 744886, "total": 5948597, "user": 3753437 } } ], "temperatures": [] } } ``` Note that this doesn't work on other websites like lemmy.world, only google. What I am confused about is that I can replicate this behavior in Brave. Why does brave reveal this information to google, and to google only? From what I understand, it can be used for fingerprinting and tracking. Shouldn't this be patched out? Is my testing methodology flawed? Will this be fixed? Brave version: `Version 1.67.123 Chromium: 126.0.6478.126 (Official Build) unknown (64-bit)` running on linux via flatpak


Context for newbies: Linux refers to network adapters (wifi cards, ethernet cards, etc.) by so called "interfaces". For the longest time, the interface names were assigned based on the type of device and the order in which the system discovered it. So, `eth0`, `eth1`, `wlan0`, and `wwan0` are all possible interface names. This, however, can be an issue: "the order in which the system discovered it" is not deterministic, which means hardware can switch interface names across reboots. This can be a real issue for things like servers that rely on interface names staying the same. The solution to this issue is to [assign custom names based on MAC address](https://wiki.alpinelinux.org/wiki/Custom_network_interface_names). The MAC address is hardcoded into the network adaptor, and will not change. (There are other ways to do this as well, such as setting udev rules). Redhat, however, found this solution too simple and instead devised [their own scheme](https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/7/html/networking_guide/sec-understanding_the_predictable_network_interface_device_names) for assigning network interface names. It [fails at solving the problem](https://bbs.archlinux.org/viewtopic.php?id=245428) it was created to solve while making it much harder to type and remember interface names. To disable predictable interface naming and switch back to the old scheme, add `net.ifnames=0` and `biosdevname=0` to your boot paramets. The template for this meme is called "stop doing math".

Template source: https://web.archive.org/web/20210304000634/https://www.government.nl/topics/coronavirus-covid-19/visiting-the-netherlands-from-abroad/checklist
Template source: https://web.archive.org/web/20210304000634/https://www.government.nl/topics/coronavirus-covid-19/visiting-the-netherlands-from-abroad/checklist

Firefox on Debian stable is so old that websites yell at you to upgrade to a newer browser. And last time I tried installing Debian testing (or was it debian unstable?), the installer shat itself trying to make the bootloader. After I got it to boot, apt refused to work because of a missing symlink to busybox. Why on earth do they even need busybox if the base install already comes with full gnu coreutils? I remember Debian as the distro that Just Wroks(TM), when did it all go so wrong? Is anyone else here having similar issues, or am I doing something wrong?

Context: Permissive licenses (commonly referred to as "cuck licenses") like the MIT license allow others to modify your software and release it under an unfree license. Copyleft licenses (like the Gnu General Public License) mandate that all derivative works remain free. Andrew Tanenbaum developed MINIX, a modular operating system kernel. Intel went ahead and used it to build Management Engine, arguably one of the most widespread and invasive pieces of malware in the world, without even as much as telling him. There's nothing Tanenbaum could do, since the MIT license allows this. Erik Andersen is one of the developers of Busybox, a minimal implementation of that's suited for embedded systems. Many companies tried to steal his code and distribute it with their unfree products, but since it's protected under the GPL, Busybox developers [were able to sue them](https://en.wikipedia.org/wiki/BusyBox#GPL_lawsuits) and gain some money in the process. Interestingly enough, Tanenbaum [doesn't seem to mind](https://www.cs.vu.nl/~ast/intel/) what intel did. But there are [some examples](https://donatstudios.com/License-Grumbles) out there of people regretting releasing their work under a permissive license.

Explanation: Python is a programming language. Numpy is a library for python that makes it possible to run large computations much faster than in native python. In order to make that possible, it needs to keep its own set of data types that are different from python's native datatypes, which means you now have two different `bool` types and two different sets of `True` and `False`. Lovely. Mypy is a type checker for python (python supports static typing, but doesn't actually enforce it). Mypy treats numpy's `bool_` and python's native `bool` as incompatible types, leading to the asinine error message above. Mypy is "technically" correct, since they are two completely different classes. But in practice, there is little functional difference between `bool` and `bool_`. So you have to do dumb workarounds like declaring every bool values as `bool | np.bool_` or casting `bool_` down to `bool`. Ugh. Both [numpy](https://github.com/numpy/numpy/issues/18876) and [mypy](https://github.com/python/mypy/issues/10385) declared this issue a WONTFIX. Lovely.

Credit for the answer used in the right panel: https://serverfault.com/a/841150



Please dont take this seriously guys its just a dumb meme I haven't written a single line of code in half of these languages

Many "alternative" search engines are better for privacy, but they are still vulnerable to censorship, because they rely on g\*\*gle and m\*crosoft's indices for their search results. This isn't a deep-hidden secret either, many of them disclose what search index they use on the "about" page, for example: - https://duckduckgo.com/duckduckgo-help-pages/results/sources/ - https://support.startpage.com/hc/en-us/articles/5138782571796-Why-isn-t-a-particular-site-appearing-in-the-results - https://www.ecosia.org/privacy There are still search engines that (claim to) maintain their own index. Most surprisingly, br\*ve: - https://brave.com/search-independence/





I recently wanted to run [tegaki](https://tegaki.github.io/), and my experience is pretty much summed up by the meme. I consider myself fairly tech-savvy, but I just couldn't figure out how to compile it. So I just gave up, downloaded the `.exe` and put it into a fresh wine prefix. After installing CJK fonts, everything ran fine. Now I'm trying to get [gpaint](https://www.gnu.org/software/gpaint/) to work. ~~My distro recently dropped support for `gtk+2` (which I am fairly pissed about, since it's the last good version of GTK+), so I have to set *that* up manually as well.~~ **[[[ EDIT: gtk2 is alive and well. I was just being and idiot and searching for `gtk2`, when the package is actually called `gtk+2`. ]]]** I installed all of the dependencies that `./configure` told me to, but I still kept getting obscure errors when running `make`. So, here's my question: what tools make the process of running abandonware easier? Docker containers? Also, what can I use to package abandonware in order to make it easy for *other* people to run? Flatpak? Appimages? Any advice is appreciated! Also, inb4 "just find a modern alternative". That would be a reasonable solution. I don't want reasonable solutions!

Context: Even though Chromium has native support for AVIF, a very nice image format, Microsoft goes out of their way to remove it from Edge, which is a chromium fork. Jpeg XL (JXL) (not to be confused with Jpeg (JPG) or Jpeg 2000 (jpg2k) ) is another nice image format, which, IIRC, is only supported in Firefox.


Context: https://www.youtube.com/watch?v=fqhPUmyrfGI Without ads/tracking: https://www.yewtu.be/watch?v=fqhPUmyrfGI

{kind=link}