Sidebar
Machine Learning | Artificial Intelligence
Unsplash has a ton of free content and a great api - so I used the hugchat api to generate search queries based on some user input text and fetched images from there. Buggy test site (using all free api's so will break frequently, free Unsplash* api is 50 pics/h) here: [http://aisitegeneration.devsoft.co.za](http://aisitegeneration.devsoft.co.za) *sorry Unsplash I haven't added the attribution for photo's yet, I will soon ok? Thoughts on this approach vs generative AI?
I am currently trying to get a bit more into ML, for me that means playing with it in some context I know already or applying it to something interesting - either way I am aware this whole endeavor is a bit of stretch and having a good grasp on machine learning requires a good mathematical knowledge. In my off time I have been recreating a digital copy of a table card game called Scout: For The Show and I had the great idea to try and make an autonomous agent based on Machine Learning for it (definitely the best starting idea */s* but there is still a lot to learn in failures). First, I did the naive thing, imagined the inputs and outputs from a players perspective - current hand, amount of turns taken, count of cards in other player hands, ... but my intuition tells me this is in some way very wrong (?), the "shapes" of these inputs/outputs are weird - I don't think the model would respond with a valid move anytime soon during training like this, if ever. Second, I've then searched far and wide for card games and machine learning and found some resources where they usually reduce the problem space as much as possible and apply the model only on a subset of the information (often represented in completely different formats/dimensions - Markov Decision Process). Obviously I am not asking for the mathematical analysis of the game in question, in broad sense I am looking for any kind of pointers that might apply here, I am aware this is a very brute-force approach for something that should be carefully mathematically analyzed and from that a model could be derived. Thanks for any pointers, wisdoms or ideas! --- Notes: I am coming from a software development background - Python mainly, so it's not that far for me programming wise, and I have already played with YOLO models though only as user. The Scout card game has 45 cards with a number (1-10) on the top and bottom, the main objective is to capture points by playing stronger card combinations, either pairs/triples/x of a single number (1-1-1, 9-9, ...) or sequences/straights (2-3, 5-6-7-8, ...). The twist is that cards in hand can't be moved or flipped around, only the top side number is important for most of the game (and each variation of the top/bottom numbers is contained only once, 1/10 and 10/1 is the same card, only flipped). Players take turns in either playing a new hand on the table (Show - capturing the remaining hand, scoring) or taking a one card from the table (Scout) and putting it anywhere in their hand, even flipping top/bottom) Resources I have found: https://www.youtube.com/watch?v=IQLkPgkLMNg (Great explanation of the problems with solved/unsolved games, minimax, MCTS etc) https://www.youtube.com/watch?v=vXtfdGphr3c (Reinforced Learning)
cross-posted from: https://slrpnk.net/post/5501378 > For folks who aren't sure how to interpret this, what we're looking at here is early work establishing an upper bound on the complexity of a problem that a model can handle based on its size. Research like this is absolutely essential for determining whether these absurdly large models are actually going to achieve the results people have already ascribed to them on any sort of consistent basis. Previous work on monosemanticity and superposition are relevant here, particularly with regards to unpacking where and when these errors will occur. > > I've been thinking about this a lot with regards to how poorly defined the output space they're trying to achieve is. Currently we're trying to encode one or more human languages, logical/spatial reasoning (particularly for multimodal models), a variety of writing styles, and some set of arbitrary facts (to say nothing of the nuance associated with these facts). Just by making an informal order of magnitude argument I think we can quickly determine that a lot of the supposed capabilities of these massive models have strict theoretical limitations on their correctness. > > This should, however, give one hope for more specialized models. Nearly every one of the above mentioned "skills" is small enough to fit into our largest models with absolute correctness. Where things get tough is when you fail to clearly define your output space and focus training so as to maximize the encoding efficiency for a given number of parameters.
I am looking to build a PC where I can run some LLMs and also pytorch and maybe some video encoding and I was wondering what is the best price wise GPU with at least 16GB of VRAM that I can buy right now. For the record I really hate NVIDIA and I would prefer not to give them my money, but if it is the only viable option I would probably wait till they release the 4070 Ti Super, but what about the AMD (7800 XT) GPUs or the Arc A770? Are they going to work? In the past I had an AMD GPU and making ROCm work with it was a pain in the ***.


Ahoy there, matey! Welcome aboard Big Top Entertainment, the finest entertainment company on the seven seas!
cross-posted from: https://slrpnk.net/post/3892266 > **Institution:** Cambridge > **Lecturer:** Petar Velickovic > **University Course Code:** seminar > **Subject:** #math #machinelearning #neuralnetworks > **Description:** Deriving graph neural networks (GNNs) from first principles, motivating their use, and explaining how they have emerged along several related research lines.
 www.youtube.com
www.youtube.com
cross-posted from: https://slrpnk.net/post/3863486 > **Institution**: MIT > **Lecturer**: Prof. Manolis Kellis > **University Course Code**: MIT 6.047 > **Subject**: #biology #computationalbiology #machinelearning More at !opencourselectures@slrpnk.net
Hello, ML enthusiasts! 🚀🤖 We analyzed rotational equilibria in our latest work, **ROTATIONAL EQUILIBRIUM: HOW WEIGHT DECAY BALANCES LEARNING ACROSS NEURAL NETWORKS** 💡 **Our Findings:** Balanced average rotational updates (effective learning rate) across all network components may play a key role in the effectiveness of AdamW. 🔗 [ROTATIONAL EQUILIBRIUM: HOW WEIGHT DECAY BALANCES LEARNING ACROSS NEURAL NETWORKS](https://arxiv.org/abs/2305.17212) Looking forward to hearing your thoughts! Let’s discuss more about this fascinating topic together!

 www.quantamagazine.org
www.quantamagazine.org
Pretty cool thinking and promising early results.

 www.quantamagazine.org
www.quantamagazine.org
This is about Benjamin Grimmer's paper https://arxiv.org/abs/2307.06324 where he proves under certain conditions that large steps lead to faster convergence.
I've got a bot running/in development to detect and flag toxic content on Lemmy but I'd like to improve on it as I'm getting quite a few false positives. I think that part of the reason is that what constitutes toxic content often depends on the parent comment or post. During a recent postgrad assignment I was taught (and saw for myself) that a bag of words model usually outperforms LSTM or transformer models for toxic text classification, so I've run with that, but I'm wondering if it was the right choice. Does anyone have any ideas on what kind of model would be most suitable to include a parent as context, but to not explicitly consider whether the parent is toxic? I'm guessing some sort of transformer model, but I'm not quite sure how it might look/work.
Hi everyone, sorry if this is not the right community, just let me know if so. I'm wondering if anyone has any recommendations for which job agencies to register with for ML Jobs. I have experience with Python using mainly Pytorch and a bit of tensorflow a few years ago.
 techpolicy.press
techpolicy.press
cross-posted from: https://lemmy.ml/post/2811405 > "We view this moment of hype around generative AI as dangerous. There is a pack mentality in rushing to invest in these tools, while overlooking the fact that they threaten workers and impact consumers by creating lesser quality products and allowing more erroneous outputs. For example, earlier this year America’s National Eating Disorders Association fired helpline workers and attempted to replace them with a chatbot. The bot was then shut down after its responses actively encouraged disordered eating behaviors. "

I am an ML engineer/researcher but have never looked into music before. Some quick googling gives plenty of websites doing automatic music generation but not sure what methods/ architectures are being used. I'm sure I could find papers with more searching but hoping someone can give me a summary of current SOTA and maybe some links to code/models to get started on.
where can i go to learn about and discuss facebook's llama 2 source code? there aren't many comments in the code.
The MLOps community is flooding tools and pipeline orchestration tools. What does your stack look like?

 www.nature.com
www.nature.com
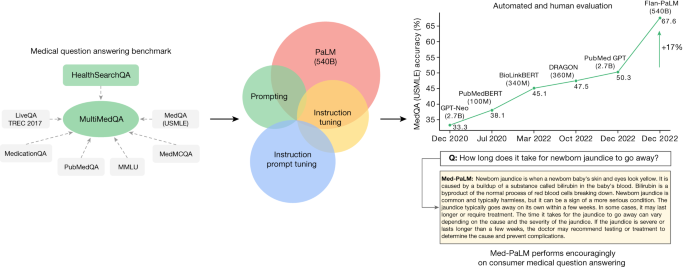
An update on Google's efforts at LLMs in the medical field.



 www.youtube.com
www.youtube.com
Great series on machine learning. Posting for anyone interested in more of the details on the AI's and LLM's and how they're built/trained.

In the hidden layer, the activation function will decide what is being determined by the neural network, is it possible for an AI to generate activation function for itself so it can improve upon itself?
 www.platformer.news
www.platformer.news
Hi lemmings, what do you think about this and do you see a parallel with the human mind ? > ... "A second, [more worrisome study](https://arxiv.org/pdf/2305.17493v2.pdf) comes from researchers at the University of Oxford, University of Cambridge, University of Toronto, and Imperial College London. It found that training AI systems on data generated by other AI systems — synthetic data, to use the industry’s term — causes models to degrade and ultimately collapse" ...
cross-posted from: https://lemmy.world/post/811496 > Huge news for AMD fans and those who are hoping to see a real* open alternative to CUDA that isn't OpenCL! > > **: Intel doesn't count, they still have to get their shit together in rendering things correctly with their GPUs.* > > >We plan to expand ROCm support from the currently supported AMD RDNA 2 workstation GPUs: the Radeon Pro v620 and w6800 to select AMD RDNA 3 workstation and consumer GPUs. Formal support for RDNA 3-based GPUs on Linux is planned to begin rolling out this fall, starting with the 48GB Radeon PRO W7900 and the 24GB Radeon RX 7900 XTX, with additional cards and expanded capabilities to be released over time.

 www.mosaicml.com
www.mosaicml.com
and another commercially viable open-source LLM!
 news.mit.edu
news.mit.edu
TLDR Summary: - MIT researchers developed a 350-million-parameter self-training entailment model to enhance smaller language models' capabilities, outperforming larger models with 137 to 175 billion parameters without human-generated labels. - The researchers enhanced the model's performance using 'self-training,' where it learns from its own predictions, reducing human supervision and outperforming models like Google's LaMDA, FLAN, and GPT models. - They developed an algorithm called 'SimPLE' to review and correct noisy or incorrect labels generated during self-training, improving the quality of self-generated labels and model robustness. - This approach addresses inefficiency and privacy issues of larger AI models while retaining high performance. They used 'textual entailment' to train these models, improving their adaptability to different tasks without additional training. - By reformulating natural language understanding tasks like sentiment analysis and news classification as entailment tasks, the model's applications were expanded. - While the model showed limitations in multi-class classification tasks, the research still presents an efficient method for training large language models, potentially reshaping AI and machine learning.
TLDR summary: 1. Researchers at MIT and Tufts University have developed an AI model called ConPLex that can screen over 100 million drug compounds in a day to predict their interactions with target proteins. This is much faster than existing computational methods and could significantly speed up the drug discovery process. 2. Most existing computational drug screening methods calculate the 3D structures of proteins and drug molecules, which is very time-consuming. The new ConPLex model uses a language model to analyze amino acid sequences and drug compounds and predict their interactions without needing to calculate 3D structures. 3. The ConPLex model was trained on a database of over 20,000 proteins to learn associations between amino acid sequences and structures. It represents proteins and drug molecules as numerical representations that capture their important features. It can then determine if a drug molecule will bind to a protein based on these numerical representations alone. 4. The researchers enhanced the model using a technique called contrastive learning, in which they trained the model to distinguish real drug-protein interactions from decoys that look similar but do not actually interact. This makes the model less likely to predict false interactions. 5. The researchers tested the model by screening 4,700 drug candidates against 51 protein kinases. Experiments confirmed that 12 of the 19 top hits had strong binding, including 4 with extremely strong binding. The model could be useful for screening drug toxicity and other applications. 6. The new model could significantly reduce drug failure rates and the cost of drug development. It represents a breakthrough in predicting drug-target interactions and could be further improved by incorporating more data and molecular generation methods. 7. The model and data used in this research have been made publicly available for other scientists to use.