LocalLLaMA
Zetaphor
•
12 months ago
•
100%
Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes
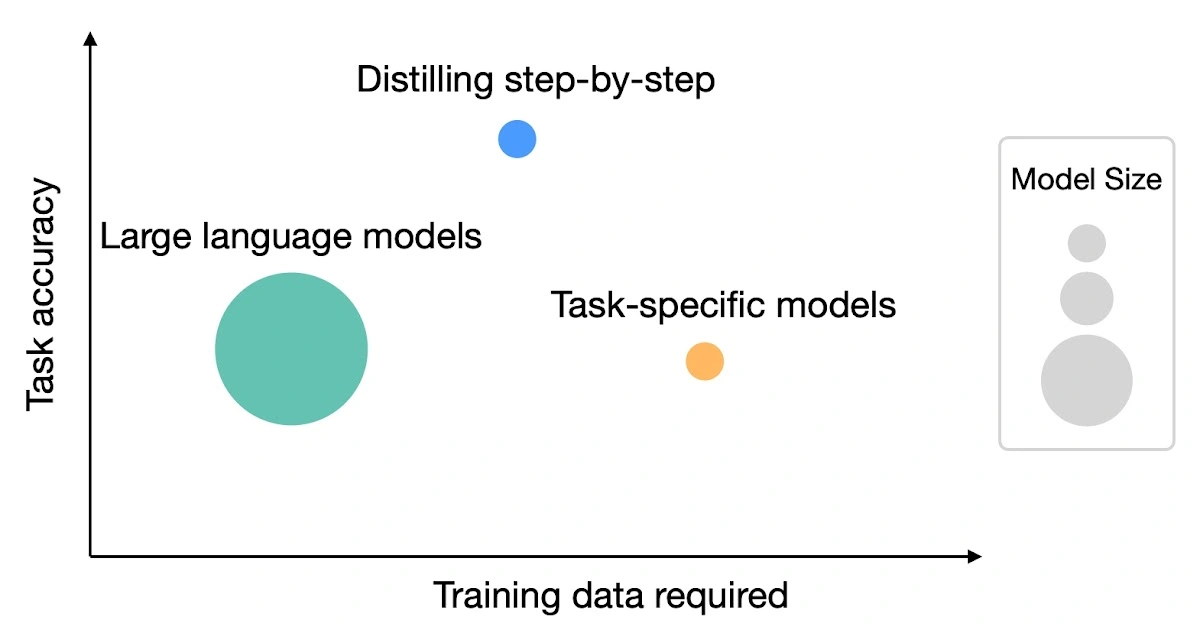 blog.research.google
blog.research.google
Comments 3
blog.research.google