Sidebar
Thai Natural Language Processing
Open Corpus, Datasets, and model for Thai Natural Language Processing
 commonvoice.mozilla.org
commonvoice.mozilla.org
ขอบคุณทุกท่านที่ช่วยเข้าไปฟังเสียง อัดเสียง เลือกประโยค เพิ่มประโยคครับ
FOSS Asia Summit จะมีเรื่อง Common Voice นะครับทุ่มนึง คุณ Robert Reyes พูดครับ
 github.com
github.com
ผมทำ JSON-RPC server สำหรับโปรแกรมตัดคำ โดยสรุปคือรันแบบนี้เลย คำสั่งเดียว ``` docker run -d --name wordcut --net=host veer66/wordcut-json-rpc-server ``` ในตัวอย่างนี้ผมเรียกใช้งานจาก PHP แต่จริง ๆ ใช้อย่างอื่นก็ได้ ```php <?php require __DIR__ . '/vendor/autoload.php'; use JsonRPC\Client; $client = new Client("http://localhost:8999"); var_dump($client->execute("put_delimiters", ["กากากา", "|"])); ?> ```

 commonvoice.mozilla.org
commonvoice.mozilla.org
via https://www.facebook.com/groups/thainlp/permalink/1509690966079055/ [@wannaphong@lemmy.ml](https://lemmy.ml/u/wannaphong)
 github.com
github.com
PyThaiNLP v3.0.0-beta0 released! #PyThaiNLP #ThaiNLP PyThaiNLP 3.0 have many improvement and new features to help you in Thai language processing tasks. This release is PyThaiNLP v3.0.0-beta0. It is The first beta release of PyThaiNLP 3.0.
ผมลองติดตั้งโปรแกรมตัดคำชำฆ้อบน Windows ดูก็ใช้ได้ครับ ตามภาพผมใช้ Windows Terminal เปิด Powershell ขึ้นมา หรือจะใช้ vscode เปิด Powershell ก็ได้ครับ แล้วใช้คำสั่งตามนี้ครับ ``` PS C:\ex1> $OutputEncoding = [console]::InputEncoding = [console]::OutputEncoding = New-Object System.Text.UTF8Encoding PS C:\ex1> Invoke-WebRequest -uri https://github.com/veer66/chamkho/releases/download/1.1.0/chamkho-1.1.0-windows-amd64.zip -OutFile chamkho.zip PS C:\ex1> Expand-Archive -Path .\chamkho.zip -DestinationPath . PS C:\ex1> cd .\chamkho-1.1.0-windows-amd64\ PS C:\ex1\chamkho-1.1.0-windows-amd64> echo ฉันง่วงมาก | .\wordcut. exe ``` 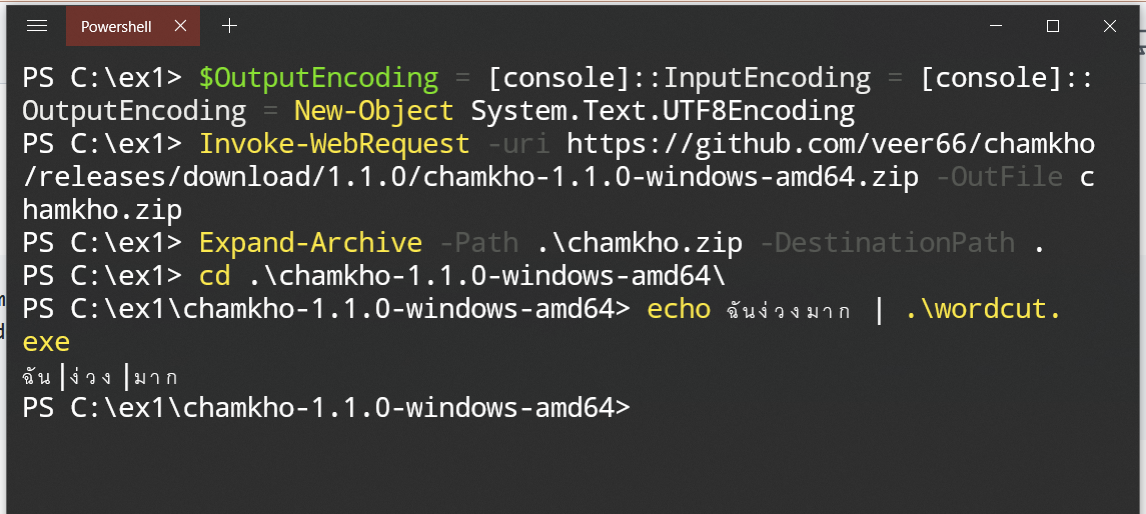
ผมเอา chamkho ที่เป็นโปรแกรมตัดคำตัวหนึ่งให้มิตรสหายใช้ รู้สึกว่าขั้นตอนเยอะไป จึงแก้ให้ติดตั้งง่ายขึ้น วิธีติดตั้งและใช้งานตามด้านล่างครับ ``` $ wget -q https://github.com/.../chamkho-1.1.0-linux-amd64.tar.gz -O - | tar -xzf - $ cd chamkho-1.1.0-linux-amd64/ $ echo ฉันง่วงมาก | ./wordcut ฉัน|ง่วง|มาก ``` ตอนนี้ใช้ได้เฉพาะ GNU/Linux
 github.com
github.com
PyThaiASR is a Python package for Automatic Speech Recognition with focus on Thai language. It have offline thai automatic speech recognition model from Artificial Intelligence Research Institute of Thailand (AIResearch.in.th).
 github.com
github.com
พรุ่งนี้จะลองกับข้อมูลจริงครับ
 huggingface.co
huggingface.co
A multilingual colossal, cleaned version of Common Crawl's web crawl corpus. Based on Common Crawl dataset: "https://commoncrawl.org".
 github.com
github.com
🔍 End-to-end Python framework for building natural language search interfaces to data. Leverages Transformers and the State-of-the-Art of NLP. Supports DPR, Elasticsearch, Hugging Face’s Hub, and much more!
OSKut: Out-of-domain StacKed cut for Word Segmentation - Github: https://github.com/mrpeerat/OSKut - Paper: https://aclanthology.org/2021.findings-acl.86.pdf - New Dataset: https://github.com/mrpeerat/OSKut/tree/main/VISTEC-TP-TH-2021 - Colab: https://colab.to/oskut
The #Apertium channel has already moved from Freenode to OFTC Apertium เป็น rule-based machine translation
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 mastodon.social
mastodon.social
Mark Watson ออกหนังสือ Practical Artificial Intelligent Programming With Clojure เล่มนี้ผมเคยอ่านแค่สารบัญ แต่จากที่อ่าน Common Lisp มา มันคือ practical มาก ๆ แบบลอก code ตามได้เลย 😅 ในเล่มนี้หลายอย่างพอของ Clojure หรือบน JVM ไม่มี library ที่ต้องการเขาก็ไปเรียกของ Python มาใช้เลย เล่มนี้ชื่อ AI แต่ก็ค่อนข้างเน้น #NLP ที่ดูผ่าน ๆ ก็ไม่ถึงกับ train model แต่ว่าเอาพวก spaCY และอื่น ๆ มาใช้ มี semantic web ด้วย https://mastodon.social/@mark_watson/106274520174482155
black จัดให้แบบนี้ ```Python elif word[i : i + 2] == _DOUBLE_RO_RUA: ``` แต่ pep8speaks บอกว่า > Line 177:20: E203 whitespace before ':' เอาแบบไหนดีครับ ?
 github.com
github.com
พี่แบคบอกว่า black นั่นล่ะคือ linter ผมก็เลยลองรันดู ``` black -l 79 pythainlp ``` ปรากฎว่าไฟล์โดนแก้เพียบเลย ``` $ git status On branch dev Your branch is up to date with 'origin/dev'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: pythainlp/benchmarks/word_tokenization.py modified: pythainlp/cli/data.py modified: pythainlp/cli/soundex.py modified: pythainlp/cli/tag.py modified: pythainlp/cli/tokenize.py modified: pythainlp/corpus/__init__.py modified: pythainlp/corpus/core.py modified: pythainlp/corpus/wordnet.py modified: pythainlp/summarize/core.py modified: pythainlp/summarize/freq.py modified: pythainlp/summarize/mt5.py modified: pythainlp/tag/_tag_perceptron.py modified: pythainlp/tag/chunk.py modified: pythainlp/tag/crfchunk.py modified: pythainlp/tag/named_entity.py modified: pythainlp/tag/pos_tag.py modified: pythainlp/tokenize/core.py modified: pythainlp/tokenize/nercut.py modified: pythainlp/translate/__init__.py modified: pythainlp/transliterate/__init__.py modified: pythainlp/transliterate/thai2rom.py modified: pythainlp/transliterate/thaig2p.py modified: pythainlp/transliterate/w2p.py modified: pythainlp/ulmfit/__init__.py modified: pythainlp/ulmfit/preprocess.py modified: pythainlp/util/keyboard.py modified: pythainlp/util/strftime.py modified: pythainlp/util/thai.py modified: pythainlp/util/trie.py modified: pythainlp/wangchanberta/core.py modified: pythainlp/wangchanberta/postag.py ``` 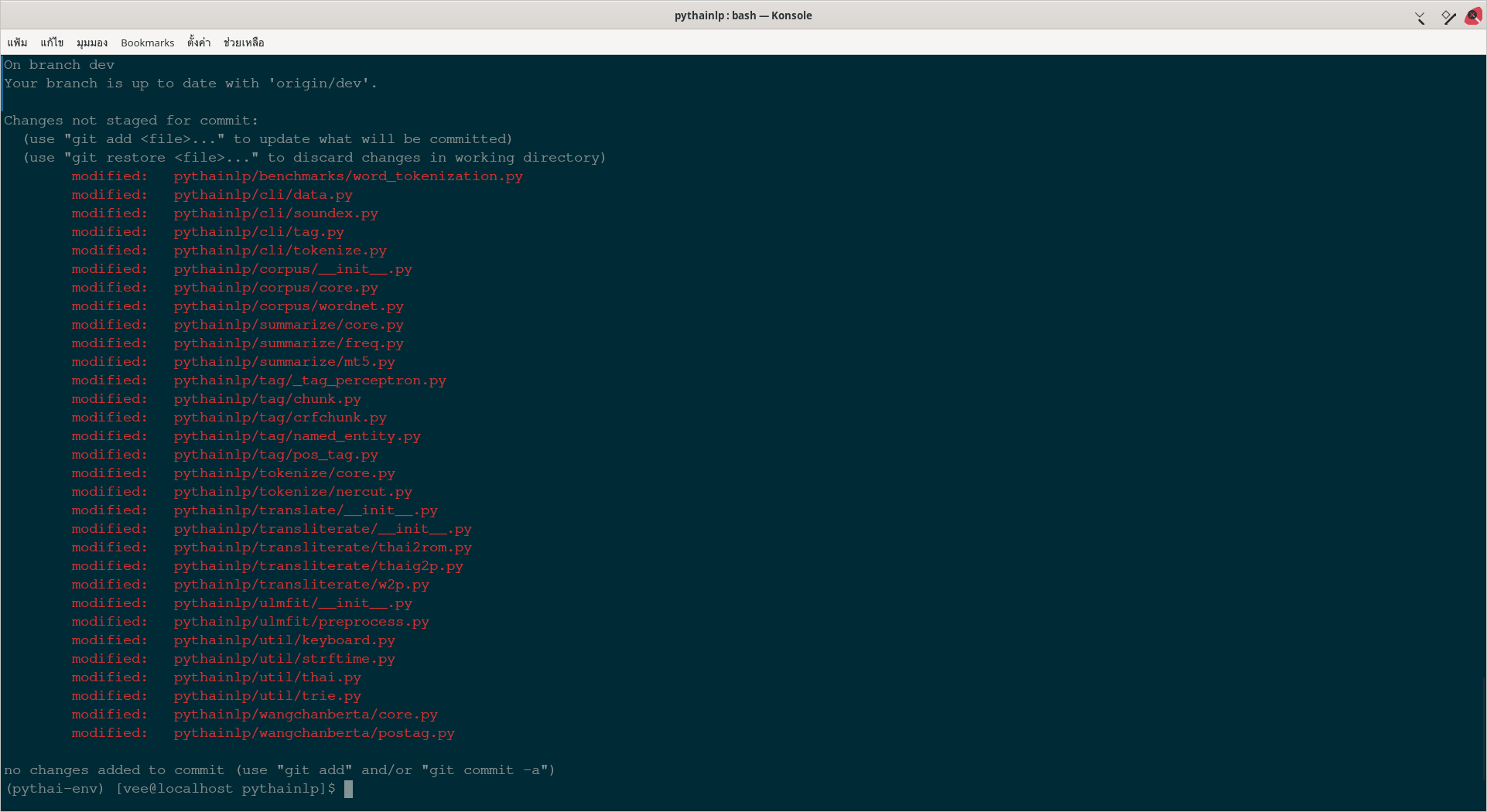 สงสัยต้องรันแบบระบุไฟล์เดียวไปเลย ?
ตอน pull request ผมเห็นมีช่องให้บอกว่าผ่าน linter แล้ว แบบนี้ ``` [ ] Passed code linting checks and unit test ``` แต่ไม่รู้ว่า Python เขาใช้อะไรกัน แล้วแต่ละ project ใช้ตัวไหน
 web.facebook.com
web.facebook.com
AI Builders ได้รับเกียรติจากอาจารย์เต้ อรรถพล ธำรงรัตนฤทธิ์ นักวิจัยประมวลผลภาษาธรรมชาติและอาจารย์ประจำภาควิชาภาษาศาสตร์ จุฬาลงกรณ์มหาวิทยาลัยมาบรรยายเกี่ยวกับการประมวลผลภาษาธรรมชาติ (Natural Language Processing; NLP) สำหรับน้องๆ AI Builders เจอกันใน gather.town เหมือนเดิม! #ทีมพี่เต้ ในหน้าสื่อ: "จากอดีตนักเรียนศิลป์-ภาษาที่มีความรู้ความสนใจในวรรณกรรม ทำผลการเรียนดีเยี่ยมจนได้รับทุนการศึกษาจากรัฐบาลไทยให้ไปศึกษาต่อที่สหรัฐอเมริกาตั้งแต่ระดับปริญญาตรี ในสถาบันชั้นนำอย่างมหาวิทยาลัยสแตนฟอร์ด (Stanford University) ที่ทำให้เขาได้ต่อยอดเอาความรู้ทางด้านภาษามาผสมผสานกับเทคโนโลยีคอมพิวเตอร์ จนสำเร็จการศึกษาล่าสุดในระดับปริญญาเอก สาขาวิทยาการคอมพิวเตอร์จาก Brandeis University ก่อนจะกลับมาเป็นอาจารย์ตามความตั้งใจ เขายังใช้เวลาราว 2 ปีไปกับการเก็บเกี่ยวประสบการณ์ของการทำงานในซิลิคอนวัลเลย์ ในฐานะ Software Engineer แห่งองค์กรจัดเก็บโปรไฟล์บุคคลที่มีชื่อเสียงในระดับโลกอย่าง LinkedIn" --a day BULLETIN (https://adaybulletin.com/talk-guest-attapol.../32103) "ผมว่าสายศิลป์มันเป็นอะไรที่ไม่มีวันตายจริงๆ เพราะสายศิลป์มันคือมนุษย์ศาสตร์ มันเกี่ยวกับมนุษย์ เราก็ยังเป็นมนุษย์อยู่วันยันค่ำ เราจะใช้เทคโนโลยีขนาดไหนก็ตาม จริงๆ เรียกว่าข้อมูลทางมนุษยศาสตร์มันเปลี่ยนไปมากกว่า แต่ก่อนมันอยู่ในหนังสือ นิตยสาร เวลาจะไปหาข้อมูลอะไร ก็ต้องไปหาในจดหมายเหตุ นิตยสารเก่าๆ แต่ตอนนี้ข้อมูลเปลี่ยนไปเป็นออนไลน์ แต่มันก็ยังคงเป็นข้อมูลทางมนุษยศาสตร์ชุดเดิม เผลอๆ มีบทบาทมากกว่าเดิมด้วย เพราะสมัยก่อน ใครจะเขียนหนังสือ จะต้องเป็นนักข่าว นักเขียน ต้องผ่านการกลั่นกรอง ผ่านสำนักพิมพ์ แต่เดี๋ยวนี้ใครๆ ก็เขียนได้แล้ว" --The Matter (https://thematter.co/social/interview-with-aj-attapol/80413) "ตอนที่ผมทำงานและเรียนอยู่อเมริกาจะเห็นได้ว่าทางด้านเทคโนโลยีบ้านเราจะตามเขาอยู่ประมาณ 5-10 ปี เพราะฉะนั้นผมเห็นแล้วว่ามันมีการประยุกต์ใช้เยอะมากเลยสำหรับภาษาศาสตร์คอมพิวเตอร์ แล้วผมว่าตอนนี้พื้นที่ในบ้านเราก็ยังมีอยู่ ไม่ใช่ทุกโจทย์ถูกตอบไปหมดแล้ว ความรู้ความเชี่ยวชาญการประมวลภาษาธรรมชาติ ซึ่งเป็นการสอนเครื่องคอมพิวเตอร์ให้ทำหน้าที่ทางภาษาแทนมนุษย์ได้ เช่น ตอบโต้กับเราได้หรือค้นหาข้อมูลให้เราได้ หรือตอบคำถามต่างๆ กำลังเป็นที่ต้องการของบริษัทในหลายด้านทั้งธุรกิจทางด้านการสื่อสาร การธนาคาร ไฟแนนซ์ ที่ปรึกษาธุรกิจ และสตาร์ทอัพต่างๆ เพราะตำแหน่งงานมีมากกว่าคนที่มีคุณสมบัติเพียงพอ ดร.อรรถพล กล่าว" --VoiceTV (https://voicetv.co.th/read/AiRqeF5fi) Speaker: ผศ.ดร.อรรถพล ธำรงรัตนฤทธิ์ (อ.เต้) ผู้เชี่ยวชาญด้านการประมวลผลภาษาธรรมชาติและ data science ปัจจุบันเป็นอาจารย์ภาคภาษาศาสตร์ คณะอักษรศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย สอนวิชาด้านภาษาศาสตร์และการประมวลภาษาธรรมชาติ ด้วยปริญญาโทถึงสามใบ ด้านสถิติ (Stanford University), neuroscience (Princeton University), computer science (Brandeis University) และปริญญาเอกด้าน computer science จาก Brandeis University อ.เต้เคยทำงานให้บริษัทยักษ์ใหญ่ระดับโลกใน Silicon Valley อย่าง Linkedin และ Yelp นอกจากนี้ปัจจุบันยังเป็น lead data instructor ให้ True Digital Academy อีกด้วย
 github.com
github.com
ไม่ได้ทำอะไรที่มีประโยชน์เท่าไหร่ แค่ลบ code ส่วนที่ไม่ได้ใช้ทิ้ง เรียกว่าฝึกหัดแล้วกัน อีกอย่างผมรัน linter ไม่เป็น
เป็นเครื่องมือสำหรับเพิ่มปริมาณข้อมูลสำหรับทำ NLP ภาษาไทยครับ โดยตอนนี้รองรับพวก WordNet, Word2Vec (Thai2Fit, BPEmb) และ FastText เหมาะกับในการทำ NLP ภาษาไทยให้มีข้อมูลมากขึ้น โดยเครื่องมือยังอยู่ในช่วงกำลังพัฒนาครับ - GitHub: https://github.com/wannaphong/thaitextaug - Docs: https://github.wannaphong.com/thaitextaug/ - Notebook: https://github.com/wannap.../thaitextaug/tree/main/notebooks 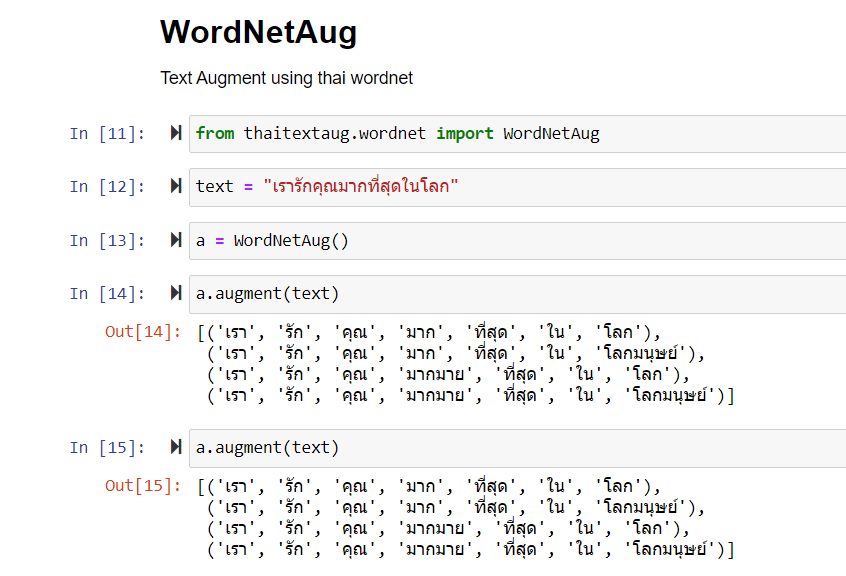 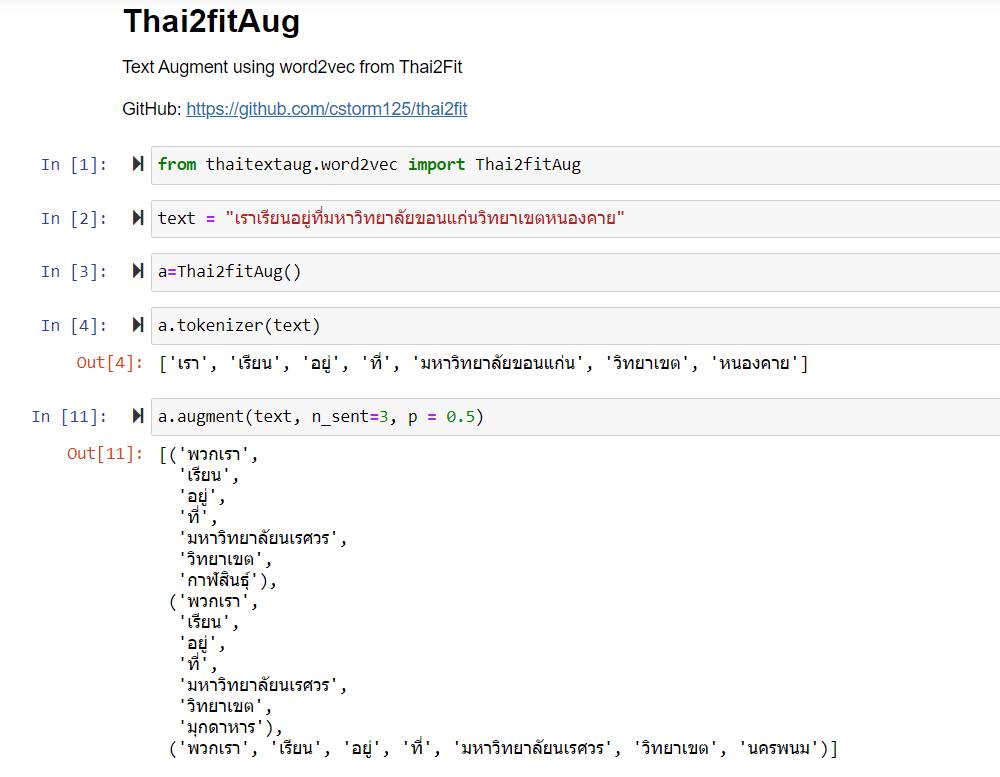 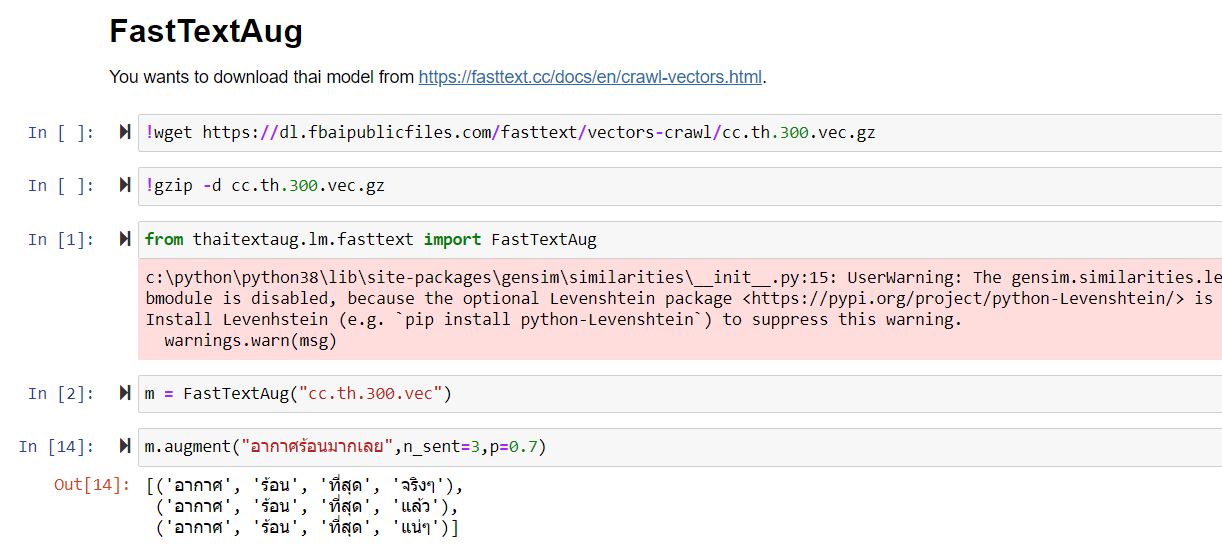
 github.com
github.com
พัฒนาโดยคุณ ธนาธิป สุนทรทิพย์ เป็นตัวตัดคำ newmm ของ pythainlp ที่นำไป port ให้ทำงานบน Rust และเรียกใช้งานผ่าน python ได้ ทำให้มีประสิทธิภาพการตัดคำและความเร็วสูงกว่า newmm ของตัว pythainlp ที่เป็น python ปกติ ท่านใดสนใจ สามารถลองได้โดยใช้คำสั่ง > pip install pythainlp-rust-modules และเข้าไปที่ [https://github.com/PyThaiNLP/oxidized-thainlp]()