Sidebar
Stable Diffusion

This is a copy of /r/stablediffusion wiki to help people who need access to that information --- Howdy and welcome to r/stablediffusion! I'm u/Sandcheeze and I have collected these resources and links to help enjoy Stable Diffusion whether you are here for the first time or looking to add more customization to your image generations. If you'd like to show support, feel free to send us kind words or check out our Discord. Donations are appreciated, but not necessary as you being a great part of the community is all we ask for. *Note: The community resources provided here are not endorsed, vetted, nor provided by Stability AI.* #Stable Diffusion ## [Local Installation](https://rentry.org/aqxqsu) Active Community Repos/Forks to install on your PC and keep it local. ## [Online Websites](https://rentry.org/tax8k) Websites with usable Stable Diffusion right in your browser. No need to install anything. ## [Mobile Apps](https://rentry.org/hxutx) Stable Diffusion on your mobile device. # [Tutorials](https://rentry.org/6zfu3) Learn how to improve your skills in using Stable Diffusion even if a beginner or expert. # [Dream Booth](https://rentry.org/vza5s) How-to train a custom model and resources on doing so. # [Models](https://rentry.org/puuat) Specially trained towards certain subjects and/or styles. # [Embeddings](https://rentry.org/6aq8q) Tokens trained on specific subjects and/or styles. # [Bots](https://rentry.org/36vtrs) Either bots you can self-host, or bots you can use directly on various websites and services such as Discord, Reddit etc # [3rd Party Plugins](https://rentry.org/r44i3) SD plugins for programs such as Discord, Photoshop, Krita, Blender, Gimp, etc. # Other useful tools * [Diffusion Toolkit](https://github.com/RupertAvery/DiffusionToolkit) - Image viewer/organizer that scans your images for PNGInfo generated. * [Pixiz Morphing](https://en.pixiz.com/template/Morphing-transition-between-2-photos-4635) - Easily transition between 2 photos. * [Bulk Image Resizing Made Easy 2.0](https://www.birme.net/?target_width=512&target_height=512) #Community ## Games * [PictionAIry](https://pictionairy.com/) : ([Video](https://www.youtube.com/watch?v=T2sNtJPqdNU)|2-6 Players) - The image guessing game where AI does the drawing! ## Podcasts * [This is Not An AI Art Podcast](https://open.spotify.com/show/4RxBUvcx71dnOr1e1oYmvV?si=9b64502c9c344ee4) - Doug Smith talks about Ai Art and provides the prompts/workflow on [his site](https://hackmd.io/@dougbtv/HkAGcsEf2). # Databases or Lists * [AiArtApps](https://www.aiartapps.com/) * [Stable Diffusion Akashic Records](https://github.com/Maks-s/sd-akashic) * [Questianon's SD Updates 1](https://rentry.org/sdupdates) * [Questianon's SD Updates 2](https://rentry.org/sdupdates2) * [SW-Yw's Stable Diffusion Repo List](https://github.com/sw-yx/prompt-eng/blob/main/README.md#sd-distros) * [Plonk's SD Model List (NSFW)](https://rentry.org/sdmodels) * [Nightkall's Useful Lists](https://www.reddit.com/r/StableDiffusion/comments/xcrm4d/useful_prompt_engineering_tools_and_resources/) * [Civitai](https://civitai.com/) \- Website with a list of custom models. **Still updating this with more links as I collect them all here.** # FAQ ## How do I use Stable Diffusion? * Check out our guides section above! ## Will it run on my machine? * Stable Diffusion requires a 4GB+ VRAM GPU to run locally. However, much beefier graphics cards (10, 20, 30 Series Nvidia Cards) will be necessary to generate high resolution or high step images. However, anyone can run it online through **[DreamStudio](https://beta.dreamstudio.ai/dream)** or hosting it on their own GPU compute cloud server. * Only Nvidia cards are officially supported. * AMD support is available **[here unofficially.](https://www.reddit.com/r/StableDiffusion/comments/wv3zam/comment/ild7yv3/?utm_source=share&utm_medium=web2x&context=3)** * Apple M1 Chip support is available **[here unofficially.](https://www.reddit.com/r/StableDiffusion/comments/wx0tkn/stablediffusion_runs_on_m1_chips/)** * Intel based Macs currently do not work with Stable Diffusion. ## How do I get a website or resource added here? *If you have a suggestion for a website or a project to add to our list, or if you would like to contribute to the wiki, please don't hesitate to reach out to us via modmail or message me.

One of the most interesting uses of diffusion models I've seen thus far.

This post is a developer diary , kind of. I'm making an improved CLIP interrogator using nearest-neighbor decoding: https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb , unlike the Pharmapsychotic model aka the "vanilla" CLIP interrogator : https://huggingface.co/spaces/pharmapsychotic/CLIP-Interrogator/discussions It doesn't require GPU to run, and is super quick. The reason for this is that the text_encodings are calculated ahead of time. I have plans on making this a Huggingface module. //----// This post gonna be a bit haphazard, but that's the way things are before I get the huggingface gradio module up and running. Then it can be a fancy "feature" post , but no clue when I will be able to code that. So better to give an update on the ad-hoc solution I have now. The NND method I'm using is described here , in this paper which presents various ways to improve CLIP Interrogators: https://arxiv.org/pdf/2303.03032  Easier to just use the notebook then follow this gibberish. We pre-encode a bunch of prompt items , then select the most similiar one using dot product. Thats the TLDR. Right now the resources available are the ones you see in the image. I'll try to showcase it at some point. But really , I'm mostly building this tool because it is very convenient for myself + a fun challenge to use CLIP. It's more complicated than the regular CLIP interrogator , but we get a whole bunch of items to select from , and can select exactly "how similiar" we want it to be to the target image/text encoding. The \{itemA|itemB|itemC\} format is used as this will select an item at random when used on the perchance text-to-image servers, in in which I have a generator where I'm using the full dataset , https://perchance.org/fusion-ai-image-generator NOTE: I've realized new users get errors when loading the fusion gen for the first time. It takes minutes to load a fraction of the sets from perchance servers before this generator is "up and running" so-to speak. I plan to migrate the database to a Huggingface repo to solve this : https://huggingface.co/datasets/codeShare/text-to-image-prompts The \{itemA|itemB|itemC\} format is also a build-in random selection feature on ComfyUI :  Source : https://blenderneko.github.io/ComfyUI-docs/Interface/Textprompts/#up-and-down-weighting Links/Resources posted here might be useful to someone in the meantime.  You can find tons of strange modules on the Huggingface page : https://huggingface.co/spaces text_encoding_converter (also in the NND notebook) : https://huggingface.co/codeShare/JupyterNotebooks/blob/main/indexed_text_encoding_converter.ipynb I'm using this to batch process JSON files into json + text_encoding paired files. Really useful (for me at least) when building the interrogator. Runs on the either Colab GPU or on Kaggle for added speed: https://www.kaggle.com/ Here is the dataset folder https://huggingface.co/datasets/codeShare/text-to-image-prompts: 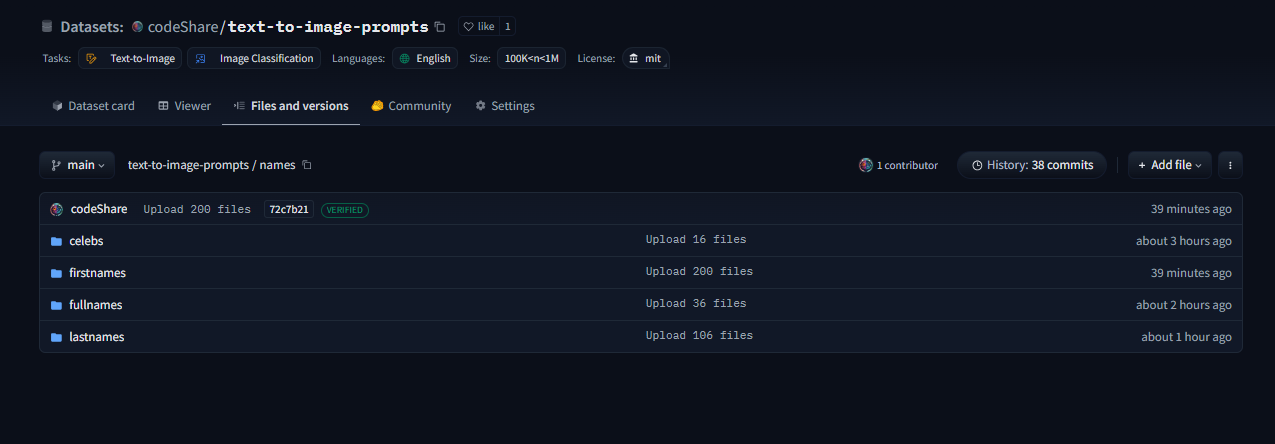 Inside these folders you can see the auto-generated safetensor + json pairings in the "text" and "text_encodings" folders. The JSON file(s) of prompt items from which these were processed are in the "raw" folder. 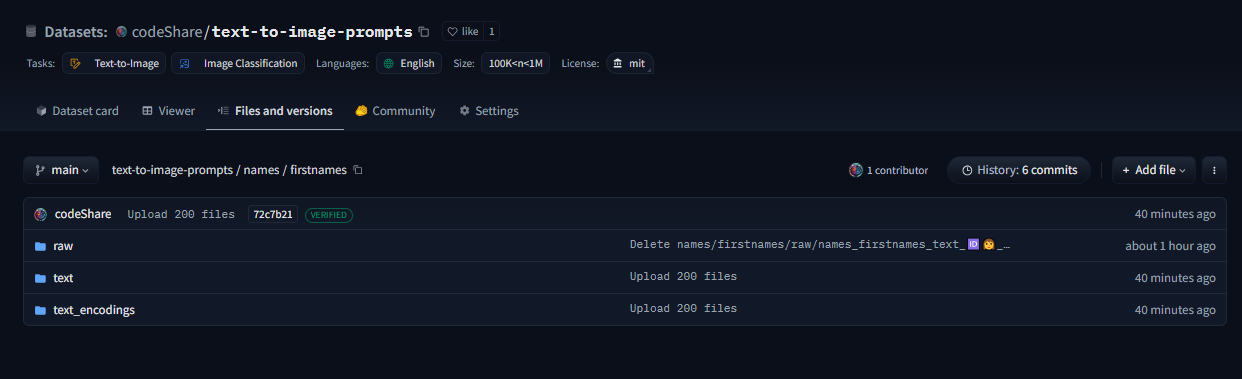 The text_encodings are stored as safetensors. These all represent 100K female first names , with 1K items in each file. By splitting the files this way , it uses way less RAM / VRAM as lists of 1K can be processed one at a time. 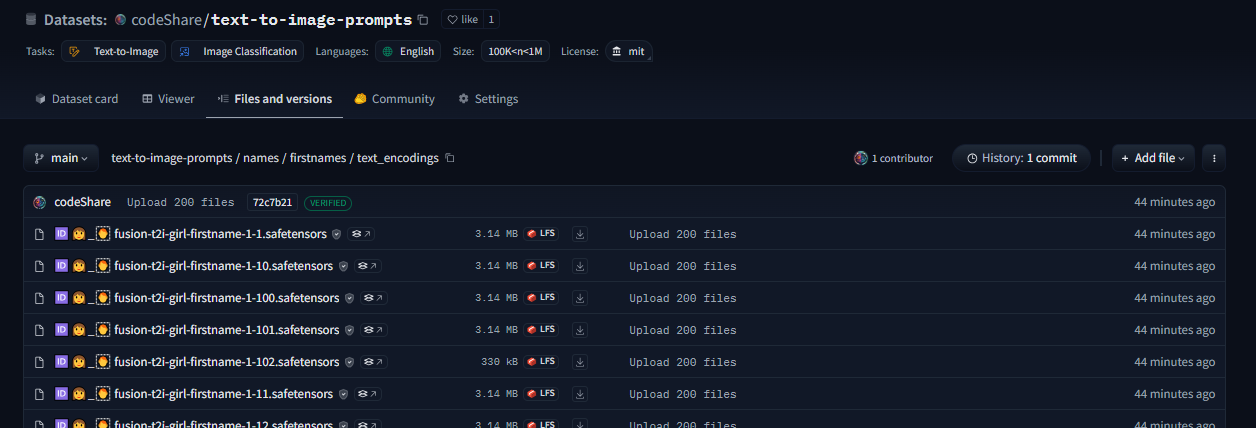 I can process roughly 50K text encodings in about the time it takes to write this post (currently processing a set of 100K female firstnames into text encodings for the NND CLIP interrogator. ) EDIT : Here is the output uploaded https://huggingface.co/datasets/codeShare/text-to-image-prompts/tree/main/names/firstnames I've updated the notebook to include a similarity search for ~100K female firstnames , 100K lastnames and a randomized 36K mix of female firstnames + lastnames Its a JSON + safetensor pairing with 1K items in each. Inside the JSON is the name of the .safetensor files which it corresponds to. This system is super quick :)! I have plans on making the NND image interrogator a public resource on Huggingface later down the line, using these sets. Will likely use the repo for perchance imports as well: https://huggingface.co/datasets/codeShare/text-to-image-prompts **Sources for firstnames : https://huggingface.co/datasets/jbrazzy/baby_names** List of most popular names given to people in the US by year **Sources for lastnames : https://github.com/Debdut/names.io** An international list of all firstnames + lastnames in existance, pretty much . Kinda borked as it is biased towards non-western names. Haven't been able to filter this by nationality unfortunately. //----// The TLDR : You can run a prompt , or an image , to get the encoding from CLIP. Then sample above sets (of >400K items, at the moment) to get prompt items similiar to that thing.


 github.com
github.com
### Highlights for 2024-09-13 Major refactor of [FLUX.1](https://blackforestlabs.ai/announcing-black-forest-labs/) support: - Full **ControlNet** support, better **LoRA** support, full **prompt attention** implementation - Faster execution, more flexible loading, additional quantization options, and more... - Added **image-to-image**, **inpaint**, **outpaint**, **hires** modes - Added workflow where FLUX can be used as **refiner** for other models - Since both *Optimum-Quanto* and *BitsAndBytes* libraries are limited in their platform support matrix, try enabling **NNCF** for quantization/compression on-the-fly! Few image related goodies... - **Context-aware** resize that allows for *img2img/inpaint* even at massively different aspect ratios without distortions! - **LUT Color grading** apply professional color grading to your images using industry-standard *.cube* LUTs! - Auto **HDR** image create for SD and SDXL with both 16ch true-HDR and 8-ch HDR-effect images ;) And few video related goodies... - [CogVideoX](https://huggingface.co/THUDM/CogVideoX-5b) **2b** and **5b** variants with support for *text-to-video* and *video-to-video*! - [AnimateDiff](https://github.com/guoyww/animatediff/) **prompt travel** and **long context windows**! create video which travels between different prompts and at long video lengths! Plus tons of other items and fixes - see [changelog](https://github.com/vladmandic/automatic/blob/master/CHANGELOG.md) for details! Examples: - Built-in prompt-enhancer, TAESD optimizations, new DC-Solver scheduler, global XYZ grid management, etc. - Updates to ZLUDA, IPEX, OpenVINO...



This is an open ended question. I'm not looking for a specific answer , just what people know about this topic. I've asked this question on Huggingface discord as well. But hey, asking on lemmy is always good, right? No need to answer here. This is a repost, essentially. This might serve as an "update" of sorts from the previous post: https://lemmy.world/post/19509682 //---// Question; FLUX model uses a combo of CLIP+T5 to create a text_encoding. CLIP is capable if doing both image_encoding and text_encoding. T5 model seems to be strictly text-to-text. So I can't use the T5 to create image_encodings. Right? https://huggingface.co/docs/transformers/model_doc/t5 But nonetheless, the T5 encoder is used in text-to-image generation. So surely, there must be good uses for the T5 in creating a better CLIP interrogator? Ideas/examples on how to do this? I have 0% knowledge on the T5 , so feel free to just send me a link someplace if you don't want to type out an essay. //----// For context; I'm making my own version of a CLIP interrogator : https://colab.research.google.com/#fileId=https%3A//huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb Key difference is that this one samples the CLIP-vit-large-patch14 tokens directly instead of using pre-written prompts. I text_encode the tokens individually , store them in a list for later use. I'm using the method shown in this paper, the "NND-Nearest neighbor decoding" .  Methods for making better CLIP interrogators: https://arxiv.org/pdf/2303.03032 T5 encoder paper : https://arxiv.org/pdf/1910.10683 Example from the notebook where I'm using the NND method on 49K CLIP tokens (Roman girl image) :  Most similiar suffix tokens : "{vfx |cleanup |warcraft |defend |avatar |wall |blu |indigo |dfs |bluetooth |orian |alliance |defence |defenses |defense |guardians |descendants |navis |raid |avengersendgame }" most similiar prefix tokens : "{imperi-|blue-|bluec-|war-|blau-|veer-|blu-|vau-|bloo-|taun-|kavan-|kair-|storm-|anarch-|purple-|honor-|spartan-|swar-|raun-|andor-}"
 github.com
github.com



Created by me. Link : https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb # How does this work? Similiar vectors = similiar output in the SD 1.5 / SDXL / FLUX model CLIP converts the prompt text to vectors (“tensors”) , with float32 values usually ranging from -1 to 1. Dimensions are \[ 1x768 ] tensors for SD 1.5 , and a \[ 1x768 , 1x1024 ] tensor for SDXL and FLUX. The SD models and FLUX converts these vectors to an image. This notebook takes an input string , tokenizes it and matches the first token against the 49407 token vectors in the vocab.json : [https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main/tokenizer](https://www.google.com/url?q=https%3A%2F%2Fhuggingface.co%2Fblack-forest-labs%2FFLUX.1-dev%2Ftree%2Fmain%2Ftokenizer) It finds the “most similiar tokens” in the list. Similarity is the theta angle between the token vectors. 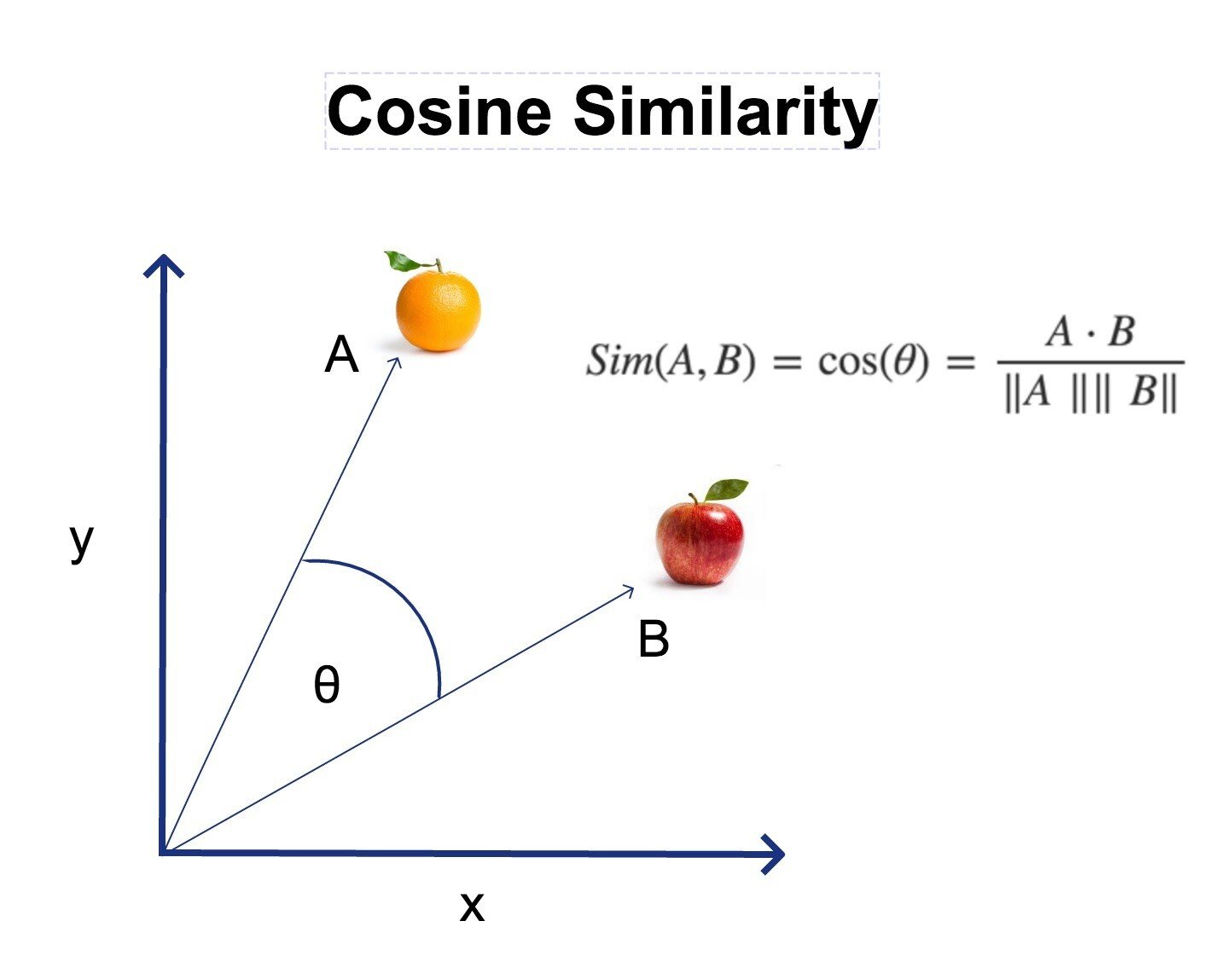 The angle is calculated using cosine similarity , where 1 = 100% similarity (parallell vectors) , and 0 = 0% similarity (perpendicular vectors). Negative similarity is also possible. # How can I use it? If you are bored of prompting “girl” and want something similiar you can run this notebook and use the “chick” token at 21.88% similarity , for example You can also run a mixed search , like “cute+girl”/2 , where for example “kpop” has a 16.71% similarity There are some strange tokens further down the list you go. Example: tokens similiar to the token "pewdiepie</w>" (yes this is an actual token that exists in CLIP) 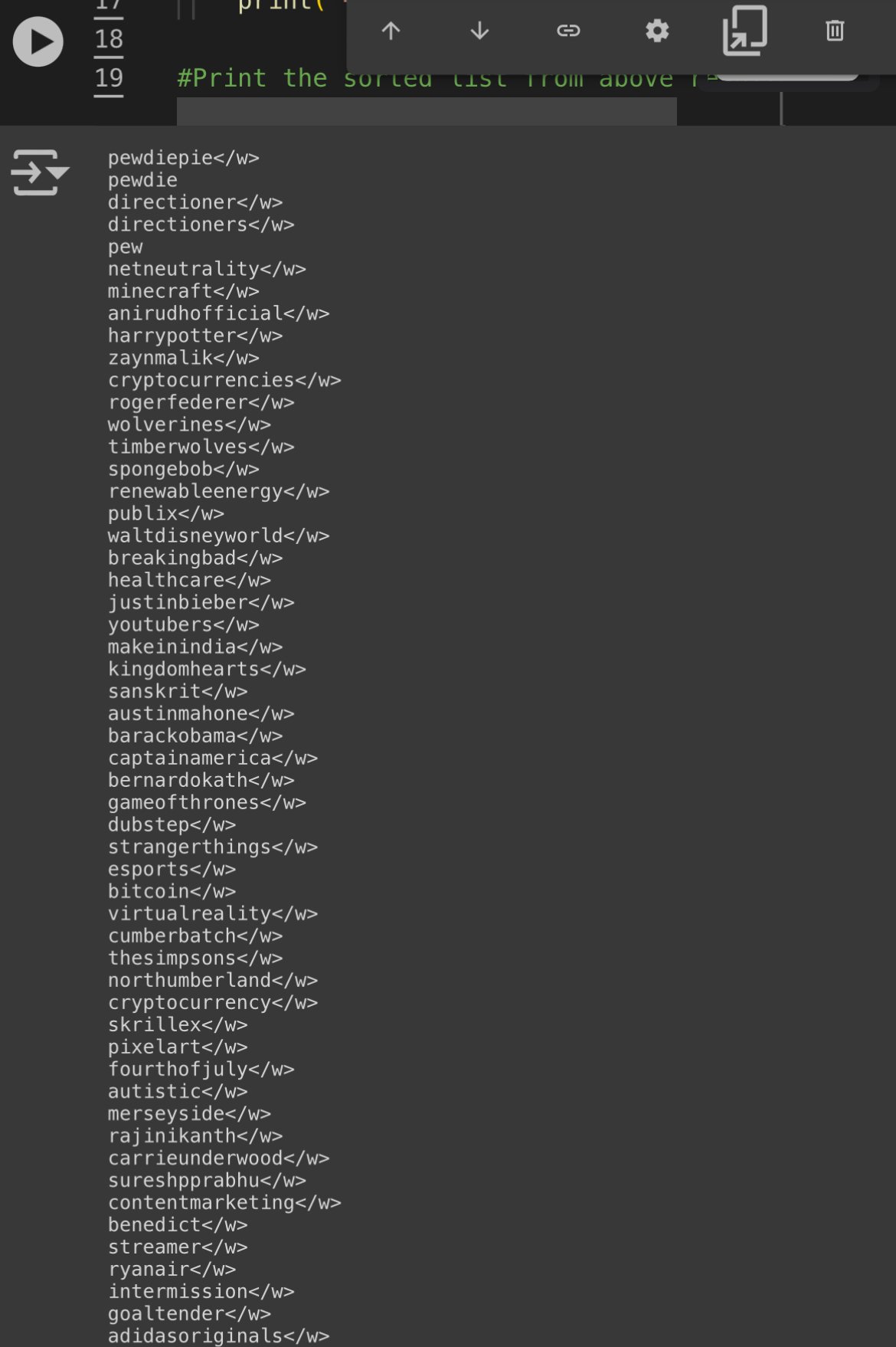 Each of these correspond to a unique 1x768 token vector. The higher the ID value , the less often the token appeared in the CLIP training data. To reiterate; this is the CLIP model training data , not the SD-model training data. So for certain models , tokens with high ID can give very consistent results , if the SD model is trained to handle them. Example of this can be anime models , where japanese artist names can affect the output greatly. Tokens with high ID will often give the "fun" output when used in very short prompts. # What about token vector length? If you are wondering about token magnitude, Prompt weights like (banana:1.2) will scale the magnitude of the corresponding 1x768 tensor(s) by 1.2 . So thats how prompt token magnitude works. Source: [https://huggingface.co/docs/diffusers/main/en/using-diffusers/weighted\_prompts](https://www.google.com/url?q=https%3A%2F%2Fhuggingface.co%2Fdocs%2Fdiffusers%2Fmain%2Fen%2Fusing-diffusers%2Fweighted_prompts)\* So TLDR; vector direction = “what to generate” , vector magnitude = “prompt weights” # How prompting works (technical summary) 1. There is no correct way to prompt. 2. Stable diffusion reads your prompt left to right, one token at a time, finding association _from_ the previous token _to_ the current token _and to_ the image generated thus far (Cross Attention Rule) 3. Stable Diffusion is an optimization problem that seeks to maximize similarity to prompt and minimize similarity to negatives (Optimization Rule) Reference material (covers entire SD , so not good source material really, but the info is there) : https://youtu.be/sFztPP9qPRc?si=ge2Ty7wnpPGmB0gi # The SD pipeline For every step (20 in total by default) for SD1.5 : 1. Prompt text => (tokenizer) 2. => Nx768 token vectors =>(CLIP model) => 3. 1x768 encoding => ( the SD model / Unet ) => 4. => _Desired_ image per Rule 3 => ( sampler) 5. => Paint a section of the image => (image) # Disclaimer /Trivia This notebook should be seen as a "dictionary search tool" for the vocab.json , which is the same for SD1.5 , SDXL and FLUX. Feel free to verify this by checking the 'tokenizer' folder under each model. vocab.json in the FLUX model , for example (1 of 2 copies) : https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main/tokenizer I'm using Clip-vit-large-patch14 , which is used in SD 1.5 , and is one among the two tokenizers for SDXL and FLUX : https://huggingface.co/openai/clip-vit-large-patch14/blob/main/README.md This set of tokens has dimension 1x768. SDXL and FLUX uses an additional set of tokens of dimension 1x1024. These are not included in this notebook. Feel free to include them yourselves (I would appreciate that). To do so, you will have to download a FLUX and/or SDXL model , and copy the 49407x1024 tensor list that is stored within the model and then save it as a .pt file. //---// I am aware it is actually the 1x768 text_encoding being processed into an image for the SD models + FLUX. As such , I've included text_encoding comparison at the bottom of the Notebook. I am also aware thar SDXL and FLUX uses additional encodings , which are not included in this notebook. * Clip-vit-bigG for SDXL: https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/README.md * And the T5 text encoder for FLUX. I have 0% understanding of FLUX T5 text_encoder. //---// If you want them , feel free to include them yourself and share the results (cuz I probably won't) :)! That being said , being an encoding , I reckon the CLIP Nx768 => 1x768 should be "linear" (or whatever one might call it) So exchange a few tokens in the Nx768 for something similiar , and the resulting 1x768 ought to be kinda similar to 1x768 we had earlier. Hopefully. I feel its important to mention this , in case some wonder why the token-token similarity don't match the text-encoding to text-encoding similarity. # Note regarding CLIP text encoding vs. token *To make this disclaimer clear; Token-to-token similarity is not the same as text_encoding similarity.* I have to say this , since it will otherwise get (even more) confusing , as both the individual tokens , and the text_encoding have dimensions 1x768. They are separate things. Separate results. etc. As such , you will not get anything useful if you start comparing similarity between a token , and a text-encoding. So don't do that :)! # What about the CLIP image encoding? The CLIP model can also do an image_encoding of an image, where the output will be a 1x768 tensor. These _can_ be compared with the text_encoding. Comparing CLIP image_encoding with the CLIP text_encoding for a bunch of random prompts until you find the "highest similarity" , is a method used in the CLIP interrogator : https://huggingface.co/spaces/pharmapsychotic/CLIP-Interrogator List of random prompts for CLIP interrogator can be found here, for reference : https://github.com/pharmapsychotic/clip-interrogator/tree/main/clip_interrogator/data The CLIP image_encoding is not included in this Notebook. If you spot errors / ideas for improvememts; feel free to fix the code in your own notebook and post the results. I'd appreciate that over people saying "your math is wrong you n00b!" with no constructive feedback. //---// Regarding output # What are the </w> symbols? The whitespace symbol indicate if the tokenized item ends with whitespace ( the suffix "banana</w>" => "banana " ) or not (the prefix "post" in "post-apocalyptic ") For ease of reference , I call them prefix-tokens and suffix-tokens. Sidenote: Prefix tokens have the unique property in that they "mutate" suffix tokens Example: "photo of a #prefix#-banana" where #prefix# is a randomly selected prefix-token from the vocab.json The hyphen "-" exists to guarantee the tokenized text splits into the written #prefix# and #suffix# token respectively. The "-" hypen symbol can be replaced by any other special character of your choosing. Capital letters work too , e.g "photo of a #prefix#Abanana" since the capital letters A-Z are only listed once in the entire vocab.json. You can also choose to omit any separator and just rawdog it with the prompt "photo of a #prefix#banana" , however know that this may , on occasion , be tokenized as completely different tokens of lower ID:s. Curiously , common NSFW terms found online have in the CLIP model have been purposefully fragmented into separate #prefix# and #suffix# counterparts in the vocab.json. Likely for PR-reasons. You can verify the results using this online tokenizer: https://sd-tokenizer.rocker.boo/    # What is that gibberish tokens that show up? The gibberish tokens like "ðŁĺħ\</w>" are actually emojis! Try writing some emojis in this online tokenizer to see the results: https://sd-tokenizer.rocker.boo/ It is a bit borked as it can't process capital letters properly. Also note that this is not reversible. If tokenization "😅" => ðŁĺħ</w> Then you can't prompt "ðŁĺħ" and expect to get the same result as the tokenized original emoji , "😅". SD 1.5 models actually have training for Emojis. But you have to set CLIP skip to 1 for this to work is intended. For example, this is the result from "photo of a 🧔🏻♂️"  A tutorial on stuff you can do with the vocab.list concluded. Anyways, have fun with the notebook. There might be some updates in the future with features not mentioned here. //---//
 github.com
github.com
Release: https://github.com/bghira/SimpleTuner/releases/tag/v1.0


 github.com
github.com
[Changelog](https://github.com/vladmandic/automatic/blob/dev/CHANGELOG.md) ### Highlights for 2024-08-31 Summer break is over and we are back with a massive update! Support for all of the new models: - [Black Forest Labs FLUX.1](https://blackforestlabs.ai/announcing-black-forest-labs/) - [AuraFlow 0.3](https://huggingface.co/fal/AuraFlow) - [AlphaVLLM Lumina-Next-SFT](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT-diffusers) - [Kwai Kolors](https://huggingface.co/Kwai-Kolors/Kolors) - [HunyuanDiT 1.2](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers) What else? Just a bit... ;) New **fast-install** mode, new **Optimum Quanto** and **BitsAndBytes** based quantization modes, new **balanced offload** mode that dynamically offloads GPU<->CPU as needed, and more... And from previous service-pack: new **ControlNet-Union** *all-in-one* model, support for **DoRA** networks, additional **VLM** models, new **AuraSR** upscaler **Breaking Changes...** Due to internal changes, you'll need to reset your **attention** and **offload** settings! But...For a good reason, new *balanced offload* is magic when it comes to memory utilization while sacrificing minimal performance! ### Details for 2024-08-31 **New Models...** To use and of the new models, simply select model from *Networks -> Reference* and it will be auto-downloaded on first use - [Black Forest Labs FLUX.1](https://blackforestlabs.ai/announcing-black-forest-labs/) FLUX.1 models are based on a hybrid architecture of multimodal and parallel diffusion transformer blocks, scaled to 12B parameters and builing on flow matching This is a very large model at ~32GB in size, its recommended to use a) offloading, b) quantization For more information on variations, requirements, options, and how to donwload and use FLUX.1, see [Wiki](https://github.com/vladmandic/automatic/wiki/FLUX) SD.Next supports: - [FLUX.1 Dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) and [FLUX.1 Schnell](https://huggingface.co/black-forest-labs/FLUX.1-schnell) original variations - additional [qint8](https://huggingface.co/Disty0/FLUX.1-dev-qint8) and [qint4](https://huggingface.co/Disty0/FLUX.1-dev-qint4) quantized variations - additional [nf4](https://huggingface.co/sayakpaul/flux.1-dev-nf4) quantized variation - [AuraFlow](https://huggingface.co/fal/AuraFlow) AuraFlow v0.3 is the fully open-sourced largest flow-based text-to-image generation model This is a very large model at 6.8B params and nearly 31GB in size, smaller variants are expected in the future Use scheduler: Default or Euler FlowMatch or Heun FlowMatch - [AlphaVLLM Lumina-Next-SFT](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT-diffusers) Lumina-Next-SFT is a Next-DiT model containing 2B parameters, enhanced through high-quality supervised fine-tuning (SFT) This model uses T5 XXL variation of text encoder (previous version of Lumina used Gemma 2B as text encoder) Use scheduler: Default or Euler FlowMatch or Heun FlowMatch - [Kwai Kolors](https://huggingface.co/Kwai-Kolors/Kolors) Kolors is a large-scale text-to-image generation model based on latent diffusion This is an SDXL style model that replaces standard CLiP-L and CLiP-G text encoders with a massive `chatglm3-6b` encoder supporting both English and Chinese prompting - [HunyuanDiT 1.2](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers) Hunyuan-DiT is a powerful multi-resolution diffusion transformer (DiT) with fine-grained Chinese understanding - [AnimateDiff](https://github.com/guoyww/animatediff/) support for additional models: **SD 1.5 v3** (Sparse), **SD Lightning** (4-step), **SDXL Beta** **New Features...** - support for **Balanced Offload**, thanks @Disty0! balanced offload will dynamically split and offload models from the GPU based on the max configured GPU and CPU memory size model parts that dont fit in the GPU will be dynamically sliced and offloaded to the CPU see *Settings -> Diffusers Settings -> Max GPU memory and Max CPU memory* *note*: recommended value for max GPU memory is ~80% of your total GPU memory *note*: balanced offload will force loading LoRA with Diffusers method *note*: balanced offload is not compatible with Optimum Quanto - support for **Optimum Quanto** with 8 bit and 4 bit quantization options, thanks @Disty0 and @Trojaner! to use, go to Settings -> Compute Settings and enable "Quantize Model weights with Optimum Quanto" option *note*: Optimum Quanto requires PyTorch 2.4 - new prompt attention mode: **xhinker** which brings support for prompt attention to new models such as FLUX.1 and SD3 to use, enable in *Settings -> Execution -> Prompt attention* - use [PEFT](https://huggingface.co/docs/peft/main/en/index) for **LoRA** handling on all models other than SD15/SD21/SDXL this improves LoRA compatibility for SC, SD3, AuraFlow, Flux, etc. **Changes & Fixes...** - default resolution bumped from 512x512 to 1024x1024, time to move on ;) - convert **Dynamic Attention SDP** into a global SDP option, thanks @Disty0! *note*: requires reset of selected attention option - update default **CUDA** version from 12.1 to 12.4 - update `requirements` - samplers now prefers the model defaults over the diffusers defaults, thanks @Disty0! - improve xyz grid for lora handling and add lora strength option - don't enable Dynamic Attention by default on platforms that support Flash Attention, thanks @Disty0! - convert offload options into a single choice list, thanks @Disty0! *note*: requires reset of selected offload option - control module allows reszing of indivudual process override images to match input image for example: set size->before->method:nearest, mode:fixed or mode:fill - control tab includes superset of txt and img scripts - automatically offload disabled controlnet units - prioritize specified backend if `--use-*` option is used, thanks @lshqqytiger - ipadapter option to auto-crop input images to faces to improve efficiency of face-transfter ipadapters - update **IPEX** to 2.1.40+xpu on Linux, thanks @Disty0! - general **ROCm** fixes, thanks @lshqqytiger! - support for HIP SDK 6.1 on ZLUDA backend, thanks @lshqqytiger! - fix full vae previews, thanks @Disty0! - fix default scheduler not being applied, thanks @Disty0! - fix Stable Cascade with custom schedulers, thanks @Disty0! - fix LoRA apply with force-diffusers - fix LoRA scales with force-diffusers - fix control API - fix VAE load refrerencing incorrect configuration - fix NVML gpu monitoring

 github.com
github.com
# Abstract >We present GameNGen, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality. GameNGen can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU. Next frame prediction achieves a PSNR of 29.4, comparable to lossy JPEG compression. Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation. GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions. Conditioning augmentations enable stable auto-regressive generation over long trajectories. Paper: https://arxiv.org/abs/2408.14837 Project Page: https://gamengen.github.io/
 civitai.com
civitai.com


 github.com
github.com
Tutorial: https://github.com/zombieyang/sd-ppp/wiki/Tutorial:-regional-prompting-in-Photoshop-by-SD%E2%80%90PPP

https://huggingface.co/Shakker-Labs/FLUX.1-dev-ControlNet-Depth https://huggingface.co/Shakker-Labs/FLUX.1-dev-ControlNet-Union-Pro
 civitai.com
civitai.com

Text: >Emad@EMostaque > >Delighted to announce the public open source release of #StableDiffusion! > >Please see our release post and retweet! stability.ai/blog/stable-di... > >Proud of everyone involved in releasing this tech that is the first of a series of models to activate the creative potential of humanity > >11:07 AM • Aug 22, 2022



Has anyone of you stumbled upon any information on how to get it running on machines like mine, or does it just not have enough power?
 github.com
github.com
Release: https://github.com/bghira/SimpleTuner/releases/tag/v0.9.8.3
 github.com
github.com
Release: https://github.com/rupeshs/fastsdcpu/releases/tag/v1.0.0-beta.36 Additional Details: https://github.com/rupeshs/fastsdcpu/tree/main?tab=readme-ov-file#flux1-schnell-openvino-support
 education.civitai.com
education.civitai.com

{kind=link}
V2 is quantized in a better way and is 0.5 GB larger than the previous version. On Hugging Face: https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4
 huggingface.co
huggingface.co