Sidebar
Sysadmins for sysadmins
This is interesting and potentially useful for anyone, who works in the corp which does not allow Linux laptops, but you can get your hands on Macs.
 tech.michaelaltfield.net
tech.michaelaltfield.net
This article will describe [how to download an image from a (docker) container registry](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget). | [](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget) | |:--:| | Manual [Download of Container Images](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget) with wget and curl | # Intro Remember the good `'ol days when you could just download software by visiting a website and click "download"? Even `apt` and `yum` repositories were just simple HTTP servers that you could just `curl` (or `wget`) from. Using the package manager was, of course, more secure and convenient -- but you could always just download packages manually, if you wanted. But **have you ever tried to `curl` an image from a container registry**, such as docker? Well friends, I have tried. And I have the [scars](https://github.com/BusKill/buskill-app/issues/78#issuecomment-1987374445) to prove it. It was a remarkably complex process that took me weeks to figure-out. Lucky you, this article will break it down. ## Examples Specifically, we'll look at how to download files from two OCI registries. 1. [Docker Hub](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#docker-hub) 2. [GitHub Packages](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#github-packages) ## Terms First, here's some terminology used by OCI 1. OCI - [Open Container Initiative](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#what-oci) 2. blob - A "blob" in the OCI spec just means a file 3. manifest - A "manifest" in the OCI spec means a list of files ## Prerequisites This guide was written in 2024, and it uses the following software and versions: 1. debian 12 (bookworm) 2. curl 7.88.1 3. OCI Distribution Spec v1.1.0 (which, unintuitively, uses the '[/v2/](https://github.com/distribution/distribution/blob/5e75227fb213162564bab74b146300ffed9f0bbd/docs/content/spec/api.md)' endpoint) Of course, you'll need '`curl`' installed. And, to parse json, '`jq`' too. ``` sudo apt-get install curl jq ``` ## What is OCI? OCI stands for Open Container Initiative. OCI was [originally formed](https://opencontainers.org/about/overview/) in June 2015 for Docker and CoreOS. Today it's a wider, general-purpose (and annoyingly complex) way that many projects host files (that are extremely non-trivial to download). One does not simply download a file from an OCI-complianet container registry. You must: 1. Generate an authentication token for the API 2. Make an API call to the registry, requesting to download a JSON "Manifest" 3. Parse the JSON Manifest to figure out the hash of the file that you want 4. Determine the download URL from the hash 5. Download the file (which might actually be many distinct file "layers") | [](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget) | |:--:| | One does not simply [download from a container registry](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget) | In order to figure out how to make an API call to the registry, you must first read (and understand) the OCI specs [here](https://opencontainers.org/release-notices/overview/). - <https://opencontainers.org/release-notices/overview/> ## OCI APIs OCI maintains three distinct specifications: 1. image spec 2. runtime spec 3. distribution spec ### OCI "Distribution Spec" API To figure out how to download a file from a container registry, we're interested in the "distribution spec". At the time of writing, the latest "distribution spec" can be downloaded [here](https://github.com/opencontainers/distribution-spec/releases/download/v1.1.0/oci-distribution-spec-v1.1.0.pdf): - <https://github.com/opencontainers/distribution-spec/releases/tag/v1.1.0> - <https://github.com/opencontainers/distribution-spec/releases/download/v1.1.0/oci-distribution-spec-v1.1.0.pdf> The above PDF file defines a set of API endpoints that we can use to query, parse, and then figure out how to download a file from a container registry. The table from the above PDF is copied below: | ID | Method | API Endpoint | Success | Failure | |------|----------|------------------------------------|--------|-----------| | end-1 | `GET` | `/v2/` | `200` | `404`/`401` | | end-2 | `GET` / `HEAD` | `/v2/<name>/blobs/<digest>` | `200` | `404` | | end-3 | `GET` / `HEAD` | `/v2/<name>/manifests/<reference>` | `200` | `404` | | end-4a | `POST` | `/v2/<name>/blobs/uploads/` | `202` | `404` | | end-4b | `POST` | `/v2/<name>/blobs/uploads/?digest=<digest>` | `201`/`202` | `404`/`400` | | end-5 | `PATCH` | `/v2/<name>/blobs/uploads/<reference>` | `202` | `404`/`416` | | end-6 | `PUT` | `/v2/<name>/blobs/uploads/<reference>?digest=<digest>` | `201` | `404`/`400` | | end-7 | `PUT` | `/v2/<name>/manifests/<reference>` | `201` | `404` | | end-8a | `GET` | `/v2/<name>/tags/list` | `200` | `404` | | end-8b | `GET` | `/v2/<name>/tags/list?n=<integer>&last=<integer>` | `200` | `404` | | end-9 | `DELETE` | `/v2/<name>/manifests/<reference>` | `202` | `404`/`400`/`405` | | end-10 | `DELETE` | `/v2/<name>/blobs/<digest>` | `202` | `404`/`405` | | end-11 | `POST` | `/v2/<name>/blobs/uploads/?mount=<digest>&from=<other_name>` | `201` | `404` | | end-12a | `GET` | `/v2/<name>/referrers/<digest>` | `200` | `404`/`400` | | end-12b | `GET` | `/v2/<name>/referrers/<digest>?artifactType=<artifactType>` | `200` | `404`/`400` | | end-13 | `GET` | `/v2/<name>/blobs/uploads/<reference>` | `204` | `404` | In OCI, files are (cryptically) called "`blobs`". In order to figure out the file that we want to download, we must first reference the list of files (called a "`manifest`"). The above table shows us how we can download a list of files (manifest) and then download the actual file (blob). # Examples Let's look at how to download files from a couple different OCI registries: 1. [Docker Hub](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#docker-hub) 2. [GitHub Packages](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#github-packages) ## Docker Hub To see the full example of downloading images from docker hub, [click here](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#docker-hub) ## GitHub Packages To see the full example of downloading files from GitHub Packages, [click here](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget#github-packages). # Why? I wrote this article because many, many folks have inquired about how to manually download files from OCI registries on the Internet, but their simple queries are usually returned with a barrage of useless counter-questions: why the heck would you want to do that!?! The answer is varied. Some people need to get files onto a restricted environment. Either their org doesn't grant them permission to install software on the machine, or the system has firewall-restricted internet access -- or doesn't have internet access at all. ## 3TOFU Personally, the reason that I wanted to be able to download files from an OCI registry was for [3TOFU](https://tech.michaelaltfield.net/2024/08/04/3tofu/). | [](https://tech.michaelaltfield.net/2024/09/03/container-download-curl-wget) | |:--:| | Verifying Unsigned Releases with [3TOFU](https://tech.michaelaltfield.net/2024/08/04/3tofu/) | Unfortunaetly, most apps using OCI registries are *extremely* insecure. Docker, for example, will happily download malicious images. By default, [it doesn't do *any* authenticity verifications](https://security.stackexchange.com/questions/238916/how-to-pin-public-root-key-when-downloading-an-image-with-docker-pull-docker-co?noredirect=1&lq=1) on the payloads it downloaded. Even if you manually enable DCT, there's loads of [pending issues](https://github.com/docker/cli/issues/2752) with it. Likewise, the macOS package manager [brew](https://brew.sh/) has this same problem: it will happily download and install malicious code, because it doesn't use cryptography to verify the authenticity of anything that it downloads. This introduces [watering hole vulnerabilities](https://en.wikipedia.org/wiki/Watering_hole_attack) when developers use brew to install dependencies in their CI pipelines. My solution to this? [3TOFU](https://tech.michaelaltfield.net/2024/08/04/3tofu/). And that requires me to be able to download the file (for verification) on three distinct linux VMs using curl or wget. > ⚠ NOTE: 3TOFU is an approach to harm reduction. > > It is not wise to download and run binaries or code whose authenticity you cannot verify using a cryptographic signature from a key stored offline. However, sometimes we cannot avoid it. If you're going to proceed with running untrusted code, then following a [3TOFU procedure](https://tech.michaelaltfield.net/2024/08/04/3tofu/) may reduce your risk, but it's better to avoid running unauthenticated code if at all possible. ## Registry (ab)use Container registries were created in 2013 to provide a clever & complex solution to a problem: how to package and serve multiple versions of simplified sources to various consumers spanning multiple operating systems and architectures -- while also packaging them into small, discrete "layers". However, if your project is just serving simple files, then the only thing gained by uploading them to a complex system like a container registry is headaches. Why do developers do this? In the case of brew, their free hosing provider (JFrog's Bintray) [shutdown in 2021](https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/). Brew was already hosting their code on GitHub, so I guess someone looked at "GitHub Packages" and [figured it was](https://github.com/orgs/Homebrew/discussions/691) a good (read: free) replacement. Many developers using Container Registries don't need the complexity, but -- well -- they're just using it as a free place for their FOSS project to store some files, man.
 every.to
every.to
# How We Built the Internet ## Metadata - Author: Anna-Sofia Lesiv - Category: article - URL: https://every.to/p/how-we-built-the-internet ## Highlights >The internet is a universe of its own. >The infrastructure that makes this scale possible is similarly astounding—a massive, global web of physical hardware, consisting of more than [5 billion](https://www.mcgill.ca/newsroom/channels/news/pushing-speed-limit-what-will-future-internet-look-348672#:~:text=As%20of%202020%2C%20over%205,diameter%20of%20a%20human%20hair.) kilometers of fiber-optic cable, more than 574 active and planned submarine cables that span a over 1 million kilometers in length, and a constellation of more than 5,400 satellites offering connectivity from low earth orbit (LEO). >“The Internet is no longer tracking the population of humans and the level of human use. The growth of the Internet is no longer bounded by human population growth, nor the number of hours in the day when humans are awake,” [writes](https://www.comsoc.org/publications/ctn/future-internet-through-lens-history) Geoff Huston, chief scientist at the nonprofit Asia Pacific Network Information Center. >As Shannon studied the structures of messages and language systems, he realized that there was a mathematical structure that underlied *information.* This meant that information could, in fact, be quantified. >Shannon noted that all information traveling from a sender to a recipient must pass through a channel, whether that channel be a wire or the atmosphere. >Shannon’s transformative insight was that every channel has a threshold—a maximum amount of information that can be delivered reliably to a sender. >Kleinrock approached AT&T and asked if the company would be interested in implementing such a system. AT&T rejected his proposal—most demand was still in analog communications. Instead, they told him to use the regular phone lines to send his digital communications—but that made no economic sense. >What was exceedingly clever about this suite of protocols was its generality. TCP and IP did not care which carrier technology transmitted its packets, whether it be copper wire, fiber-optic cable, or radio. And they imposed no constraints on what the bits could be formatted into—video text, simple messages, or even web pages formatted in a browser. >David Clark, one of the architects of the original internet, wrote in 1978 that “we should … prepare for the day when there are more than 256 networks in the Internet.” >Fiber was initially laid down by telecom companies offering high-quality cable television service to homes. The same lines would be used to provide internet access to these households. However, these service speeds were so fast that a whole new category of behavior became possible online. Information moved fast enough to make applications like video calling or video streaming a reality. >And while it may have been the government and small research groups that kickstarted the birth of the internet, its evolution henceforth was dictated by market forces, including service providers that offered cheaper-than-ever communication channels and users that primarily wanted to use those channels for entertainment. >In 2022, video streaming comprised nearly [58 percent](https://www.sandvine.com/hubfs/Sandvine_Redesign_2019/Downloads/2022/Phenomena%20Reports/GIPR%202022/Sandvine%20GIPR%20January%202022.pdf) of all Internet traffic. Netflix and YouTube alone accounted for 15 and 11 percent, respectively. >At the time, Facebook users in Asia or Africa had a completely different experience to their counterparts in the U.S. Their connection to a Facebook server had to travel halfway around the world, while users in the U.S. or Canada could enjoy nearly instantaneous service. To combat this, larger companies like Google, Facebook, Netflix, and others began storing their content physically closer to users through CDNs, or “content delivery networks.” >Instead of simply owning the CDNs that host your data, why not own the literal fiber cable that connects servers from the United States to the rest of the world? >Most of the world’s submarine cable capacity is now either partially or entirely owned by a FAANG company—meaning Facebook (Meta), Amazon, Apple, Netflix, or Google (Alphabet). >Google, which owns a number of sub-sea cables across the Atlantic and Pacific, can deliver hundreds of terabits per second through its infrastructure. >In other words, these applications have become so popular that they have had to leave traditional internet infrastructure and operate their services within their own private networks. These networks not only handle the physical layer, but also create new transfer protocols —totally disconnected from IP or TCP. Data is transferred on their own private protocols, essentially creating digital fiefdoms. >SpaceX’s Starlink is already unlocking a completely new way of providing service to [millions](https://www.cnbc.com/2023/11/11/the-rapid-rise-of-elon-musks-starlink-satellite-internet-business.html). Its data packets, which travel to users via radio waves from low earth orbit, may soon be one of the fastest and most economical ways of delivering internet access to a majority of users on Earth. After all, the distance from LEO to the surface of the Earth is just a fraction of the length of subsea cables across the Atlantic and Pacific oceans. What is next?
 josvisser.substack.com
josvisser.substack.com
# Incantations ## Metadata - Author: Jos Visser - Category: rss - URL: https://josvisser.substack.com/p/incantations ## Highlights >The problem with incantations is that you don’t understand in what exact circumstances they work. Change the circumstances, and your incantations might work, might not work anymore, might do something else, or maybe worse, might do lots of damage. It is not safe to rely on incantations, you need to move to **understanding**.
 hross.substack.com
hross.substack.com
# How much are your 9's worth? ## Metadata - Author: Ross Brodbeck - Category: rss - URL: https://hross.substack.com/p/how-much-are-your-9s-worth ## Highlights >All nines are not created equal. Most of the time I hear an extraordinarily high availability claim (anything above 99.9%) I immediately start thinking about how that number is calculated and wondering how realistic it is. >Human beings are funny, though. It turns out we respond pretty well to simplicity and order. >Having a single number to measure service health is a great way for humans to look at a table of historical availability and understand if service availability is getting better or worse. It’s also the best way to create accountability and measure behavior over time… … as long as your measurement is reasonably accurate and not a [vanity metric](https://www.tableau.com/learn/articles/vanity-metrics). >**Cheat #1 - Measure the narrowest path possible.** This is the easiest way to cheat a 9’s metric. Many nines numbers I have seen are various version of this cheat code. How can we create a narrow measurement path? >Cheat #2 - Lump everything into a single bucket. Not all requests are created equal. >Cheat #3 - Don’t measure latency. This is an ***availability*** metric we’re talking about here, why would we care about how long things take, as long as they are successful?! >Cheat #4 - Measure total volume, not minutes. Let’s get a little controversial. >In order to cheat the metric we want to choose the calculation that looks the best, since even though we might have been having a bad time for 3 hours (1 out of every 10 requests was failing), not every customer was impacted so it wouldn’t be “fair” to count that time against us. >**Building more specific models of customer paths is manual.** It requires more manual effort and customization to build a model of customer behavior (read: engineering time). Sometimes we just don’t have people with the time or specialization to do this, or it will cost to much to maintain it in the future. >**We don’t have data on all of the customer scenarios.** In this case we just can’t measure enough to be sure what our availability is. >**Sometimes we really don’t care (and neither do our customers).** Some of the pages we build for our websites are… not very useful. Sometimes spending the time to measure (or fix) these scenarios just isn’t worth the effort. It’s important to focus on important scenarios for your customers and not waste engineering effort on things that aren’t very important (this is a very good way to create an ineffective availability effort at a company). >**Mental shortcuts matter.** No matter how much education we try, it’s hard to change perceptions of executives, engineers, etc. Sometimes it is better to pick the abstraction that helps people understand than pick the most accurate one. >**Data volume and data quality are important to measurement.** If we don’t have a good idea of which errors are “okay” and which are not, or we just don’t have that much traffic, some of these measurements become almost useless (what is the SLO of a website with 3 requests? does it matter?). What is your way of cheating nines? ;)
 blog.alexewerlof.com
blog.alexewerlof.com
How to calculate SLO
 www.theguardian.com
www.theguardian.com
cross-posted from: https://feddit.it/post/7752642 > A week of downtime and all the servers were recovered only because the customer had a proper disaster recovery protocol and held backups somewhere else, otherwise Google deleted the backups too > > Google cloud ceo says "it won't happen anymore", it's insane that there's the possibility of "instant delete everything"
 blog.cloudflare.com
blog.cloudflare.com
>(again)
by @geerlingguy@mastodon.social
We run a bit of software called tabelau, I have had to restart it over night and the server hit 113 on the load average. on a 16 core box. please tell me thats mad for any software
 blog.plerion.com
blog.plerion.com
Good overview on how it works and why being compliant does not mean being secure.
 www.theverge.com
www.theverge.com
Great article
 hross.substack.com
hross.substack.com
What the title says - pros/cons
Interesting take - RIP Redis: How Garantia Data pulled off the biggest heist in open source history https://lnkd.in/ezme7dbw #redis #opensource
 www.bbc.com
www.bbc.com
 kasdopuods.lt
kasdopuods.lt
Seni krienai tauzyja apie IT
 www.codereliant.io
www.codereliant.io
What about yours? What do you predict?

 docs.fluxninja.com
docs.fluxninja.com
Distributed rate limiting

 www.infoq.com
www.infoq.com
Everybody upgraded? Any horror stories?
sometimes i see this in "very secured" servers as well. so check web configs, especially if you takeover the server management from somebody else ;)
 learnk8s.io
learnk8s.io
Could have saved me tons of time (if I knew about it earlier)
 juliopdx.com
juliopdx.com
Network CI/CD and automation is still quite rare, so it is nice to get any interesting article in that area.

 blog.oneuptime.com
blog.oneuptime.com
A story
Nice resource
Would be interesting to dig deep in what is logical separation in this case
 whyisthisinteresting.substack.com
whyisthisinteresting.substack.com
(On the IBM System/360, microarchitectures, and sanctions)
Next - steam? ;)
 www.percona.com
www.percona.com
Could be used for disaster recovery planning or just cost savings ;)
 www.infoq.com
www.infoq.com
Hashicorp gets a bit of hate nowadays, but still life is going on
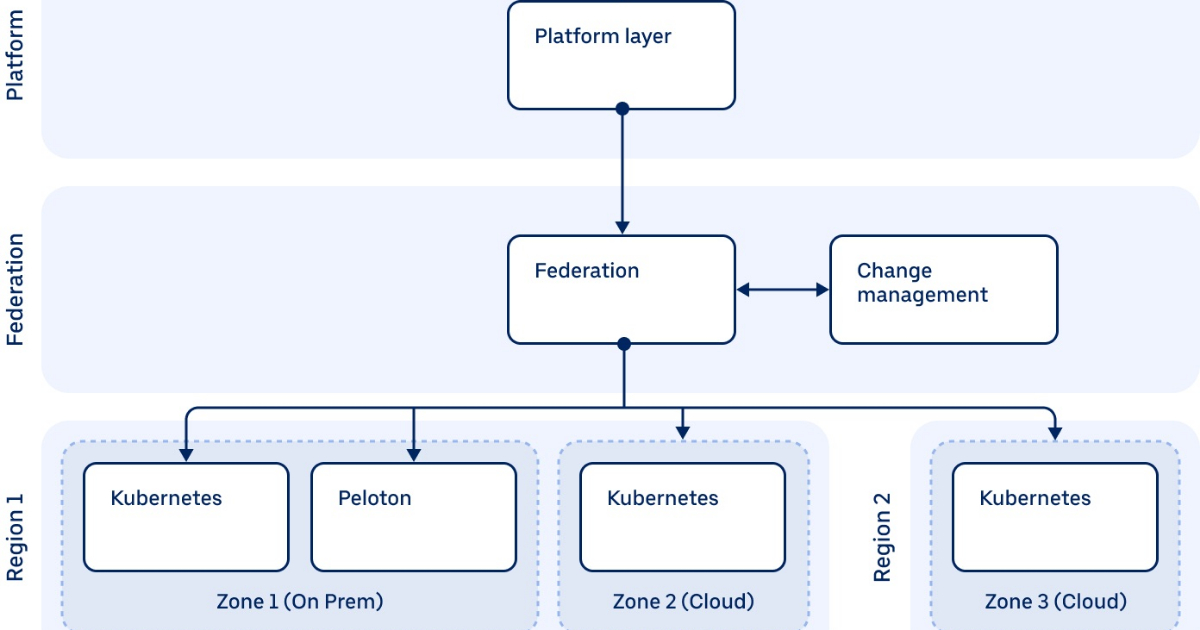 www.infoq.com
www.infoq.com
Clouds are just infrastructure nowadays
 www.srestories.dev
www.srestories.dev


 blog.railway.app
blog.railway.app